Natural Language Processing (NLP) refers to the set of mathematical models and computational algorithms capable of processing, understanding, and generating natural language either in written (a document) or spoken (an audio speech) format. Some popular examples of NLP applications are chatbots, voice assistants, automatic text translation, spam detection and sentiment analysis.
Natural language, the language spoken by humans, is complex due to the high ambiguity of meaning and grammatical roles of many words. Additionally, spoken language is much less structured than written text, and accents and regional particularities impact the understanding of different conversations. These challenges led to many advances in NLP, enabling computers to understand and generate text in a way similar to how humans do daily.
The exponential number of text data being produced every day on the internet, especially on social media, and the growing popularity of smart devices, such as Amazon Echo, are some of the driving factors leading to the increasing interest in NLP in recent years. Industries like Retail, Banking, Healthcare, and transportation are some examples of financial sectors benefiting from fast and efficient processing of large amounts of texts and audio.
I studied the key concepts, mathematical models and techniques, and applications of NLP. I also explored tools for developing NLP solutions and discussed the limitations and ethical challenges related to current NLP solutions. This enabled me to critically analyze the issues, problems, and potential opportunities pertaining to this rich research area.
An in-depth understanding of established techniques of NLP and its real-world applications.
Discuss some of the ethical issues and current challenges of NLP.
Comprehensive knowledge of the structure (morphological, synthetical, and semantical) of natural languages, with a special focus on English, together with techniques for processing these languages and extracting relevant features.
Establish a comprehensive and practical awareness of the techniques and metrics used for evaluating different NLP algorithms.
Provide a wide-ranging practical knowledge of the available libraries, programming languages, and platforms for the development of NLP solutions.
Topic
Natural Language Processing consists of the research and development of algorithms capable of understanding the structure and meaning of human language. Currently, NLP has a wide range of applications, such as Conversational Agents, Machine Translation and Sentiment Analysis.
One of the most recent applications of NLP is in the detection of hate speech and fake news in social media. Hate speech is any content that is targeted to a particular race, religion, or sexual orientation with the intention of threatening, abusing or provoking a minority social group. Fake news, on the other hand, consists of false or distorted information about certain topics intending to mislead readers. In recent years, the increasing spread of both fake news and hate speech in social media had severe impacts on many political and social sectors. Some examples of these issues are:
Fake news impacting the US elections (both 2016 and 2020[3]) and the current covid-19 vaccination campaigns (due to anti-vaccine movements on social media groups[4]).
Racist and fascist speech inciting violence against people of colour during the Black Lives Matterprotests[1] [2].
The benefits of hate speech and fake news detection in social media.
The main Natural Language Processing(NLP) solutions available for detecting both types of posts.
Your opinion on automatic hate speech/fake news detection. Do you agree, disagree, or is neutral (depends on context, applications, etc)? Explain your reasons.
References
[1] New hate crime record after racial attacks rocket during BLM protests (2021) The Independent.
[2] Kumar, S. and Pranesh, R.R. (2021) ‘TweetBLM: A Hate Speech Dataset and Analysis of Black Lives Matter-related Microblogs on Twitter’, arXiv:2108.12521 [cs] [Preprint].
[3] Bovet, A. and Makse, H.A. (2019) ‘Influence of fake news in Twitter during the 2016 US presidential election’, Nature Communications, 10(1), p. 7. doi:10.1038/s41467-018-07761-2.
[4] Germani, F. and Biller-Andorno, N. (2021) ‘The anti-vaccination infodemic on social media: A behavioral analysis’, PLOS ONE, 16(3), p. e0247642. doi:10.1371/journal.pone.0247642.
Post
The possible positive outcomes of the detection of hate speech and fake news in social media are quite comprehensive and are very important when it comes to sustaining a decent online environment. To begin, identifying and suppressing hate speech can make the digital environment be more friendly and accept that all groups in society are equal. It has been known to contribute to the manipulation of antagonistic racial, religious, or sexual groups tensions into more serious conflicts leading to violence and discrimination. Using NLP solutions to detect hate speech on social media can enable quick identification and removal of such content before it does significant damage.
With the same regard, fake news detection plays an important role in preventing information spread as wrong information can have major repercussions. However, at crucial moments such as elections or pandemics, false information can lead many to adopt a generation change in public attitudes and undermine confidence in institutions, thus even threatening the lives of citizens (Beutel, Kirschler and Kokott, 2022). Significantly, NLP algorithms help discover patterns and linguistic clues that are indicative of fake news, which allows it to be quickly determined and removed from digital venues.
For the identification of hate speech and fake news, multiple NLP solutions have been designed. Parihar et al. (2021) talk about applications and issues detection of hate speech using NLP highlighting the significance of utilizing linguistic and context features for appropriate recognition. Then, as Zhang and Ghorbani (2020) claim – the overview of online fake news also reveals that sophisticated approaches should also be implemented in order to effectively detect them since linguistic features, propagating mechanisms, and user behavior need to be taken into consideration. These NLP solutions make use of machine learning algorithms or natural language processing techniques to examine textual information and detect the underlying patterns that represent hate speech or fake news.
In my opinion, automatic hate speech and fake news detection based on NLP would allow us to combat these issues in a timely manner and at scale. But only with balancing considerations. The features such as the volume and rate of distribution of content among social networks highlight that manual moderation is simply not feasible, which also proves in favor of automatic solutions. Nevertheless, the ability of these systems is in question through false positive and what may be termed as biasness that comes with algorithmic decision making. Finding a balance between free speech and content removal is difficult, but improving the accuracy of algorithms along with algorithmic narratives can help address these problems.
Examples from real-life cases further support the idea of automation detection. Impact of misinformation is evident in the fake news and how they had an influence on the democratic processes like manifested in the 2016 US presidential election (Bovet and Makse, 2019). In addition, the information on social media about anti-vaccination shots demonstrates that incorrect data will drive safety hazards for individuals (Germani and Biller-Andorno, 2021). These cases underline the need for efficient NLP solutions to curb the social cost of hateful content and conditioning. In sum, detecting hate speech and fake news is a necessary measure that enables to create an appropriate environment for online interactions without threats to life and health.
References
Beutel, I., Kirschler, O. and Kokott, S. (2022). How do fake news and hate speech affect political discussion and target persons and how can they be detected? Central and Eastern European eDem and eGov Days, 342, pp.37–81. doi:https://doi.org/10.24989/ocg.v.342.2.
Bovet, A. and Makse, H.A. (2019). Influence of fake news in Twitter during the 2016 US presidential election. Nature Communications, 10(1). doi:https://doi.org/10.1038/s41467-018-07761-2.
Germani, F. and Biller-Andorno, N. (2021). The anti-vaccination infodemic on social media: A behavioral analysis. PLOS ONE, [online] 16(3). doi:https://doi.org/10.1371/journal.pone.0247642.
Parihar, A., Thapa, S. and Mishra, S. (2021). Hate Speech Detection Using Natural Language Processing: Applications and Challenges. 2021 5th International Conference on Trends in Electronics and Informatics (ICOEI). [online] doi:https://doi.org/10.1109/ICOEI51242.2021.9452882.
Zhang, X. and Ghorbani, A.A. (2020). An overview of online fake news: Characterization, detection, and discussion. Information Processing & Management, [online] 57(2). doi:https://doi.org/10.1016/j.ipm.2019.03.004.
Summary
Pondering on the peer and instructor conversations about the post, several important points came to light. One theme that has been repeatedly raised was the appreciation of the contribution of hate speech and fake news detection toward the building of a more sustainable digital ecosystem. In addition, there was also a consensus on the difficulties accompanying the possibility of having precision and fairness in the detections. Participants emphasized the need to consider cultural and linguistic subtleties, especially for minority groups, so as to not unwittingly make the NLP algorithms reinforce the existing biases. Moreover, discourses called for the continuous refinement and validation of detection models to address false positives and with aim of guaranteeing effective content moderation without violating the freedom of expression.
Another debate was also about the question of striking a balance between free speech and content moderation. Although automatic detection systems are scalable and perform efficiently, issues on false positives and algorithmic bias came out. The peers stressed on polishing NLP algorithms to limit the false positives and to reduce the biases which may impact minority groups disproportionately. Furthermore, a majority of the reviewed objectives indicated the importance of continuous monitoring and updating of detection systems to keep up with the changing techniques being used by the illicit actors (Parihar et al., 2021). Furthermore, the real-world instances, like the effect of misinformation on democratic norms and health, embraced the need to put in place sturdy NLP solutions to solve this problem. I got a more comprehensive picture of the multi-layered nature of hate speech and fake news detection, paying particular attention to the balance between technical knowledge and ethical issues.
Moving forward, the spotlight should be directed towards research on hate speech and fake new detection in social media by trying to eliminate bias and tracking hate sources. It concerns looking for new means to combine various linguistic and cultural overviews with the models during the detection which result in more inclusivity and better accuracy (Zhang & Ghorbani, 2020). Moreover, they should focus on the construction of Open and clear algorithms for accountability and establishing trust of users and stakeholders.
In addition to the algorithmic solutions, the fight against hate speech and fake news should also include the societal initiatives such as media literacy programs and community-based initiatives that foster critical thinking and responsible online behavior (Beutel et al., 2022). As a result of eliminating the main sources of misinformation and intolerance, we will get a resilient digital world that is based on democratic values and that guarantees the interests of the users. In the long run social media can be tactfully and systematically tackled to bring about the agenda of productive talks and eventual social reforms.
References
Beutel, I., Kirschler, O., & Kokott, S. (2022). How do fake news and hate speech affect political discussion and target persons and how can they be detected? Central and Eastern European EDem and EGov Days, 342, 37–81. https://doi.org/10.24989/ocg.v.342.2
Parihar, A., Thapa, S., & Mishra, S. (2021). Hate Speech Detection Using Natural Language Processing: Applications and Challenges. 2021 5th International Conference on Trends in Electronics and Informatics (ICOEI). https://doi.org/10.1109/ICOEI51242.2021.9452882
Zhang, X., & Ghorbani, A. A. (2020). An overview of online fake news: Characterization, detection, and discussion. Information Processing & Management, 57(2). https://doi.org/10.1016/j.ipm.2019.03.004
Kaggle is one of the largest online communities for data scientists and machine learning practitioners. It enables users to find and publish datasets, explore and build Deep Learning models, and collaborate with other data scientists and ML engineers around the world. One of its more interesting features is the Machine Learning Competitions, which attract over a thousand teams and individuals every year. These competitions consist of problems posted by companies and/or research institutions in which teams compete to build the best algorithm.
Among the most popular Kaggle competitions is the Toxic Comment Classification Challenge. This challenge occurs annually since 2018 and consist of researching and developing methods for detecting and classifying different levels of toxicity in negative and disrespectful online comments, from insults to violent threats. In this assessment, we’ll be using the dataset from the first competition for analysing the performance of different MachineLearning methods for classifying 6 types of toxicity. Details on the dataset and instructions on how to use are available here: Toxic Comment Classification Challenge.
Tasks
Perform detailed data analysis of the dataset provided by the competition, observing:
Number of sentences and tokens per class (and check if the dataset is unbalanced or not).
Analyse the most common words for each class and, therefore, understand the most used terms for each level of toxicity.
Select three Machine Learning algorithms among the ones listed below(many of these methods were explored in this module and previous ones):
Support Vector Machine (SVM)
K-Nearest Neighbours (KNN)
NaïveBayes
Decision Trees
Logistic Regression
Random Forest
Multi-LayerPerceptron
Analyse their performance in classifying the level of toxicity of different comments. Please make use of the main metrics (accuracy, F1-score, Recall, Precision, and AUC) to compare the different algorithms. Additionally, clearly explain the parameters defined for each model. Any MLpython Library can be used during implementation(such as sklearn and keras).
Consider the main Feature Extraction methods studied in previous Lectures, such as TF-IDF and WordEmbeddings. Using the same three classifier previously analysed, change the Feature Extraction method initially used (for example, if you used Word Embeddings, change to TF-IDF) and repeat the previous experiments and observe if there is any considerable difference between the new results and the previous one (i.e. if the method of feature extraction impacts the classification performance).
The analysis of the toxic comment data reveals insightful patterns and problems in detecting and classifying toxic online behavior. The initial data analysis revealed differences in the word counts and average sentence across various toxicity classes, with 'severe_toxic' remarks being longer, hinting at a probable association between a comment's verboseness and toxicity level. Besides, the class distribution highlighted a substantial unevenness, with 'toxic' comments being the most prevalent. The unevenness posed a problem for machine learning (ML) models, possibly impacting their performance and requiring approaches for rebalancing (Risch and Krestel, 2020; Dablain et al., 2023). The analysis also evaluated the performance of three ML algorithms, Logistic Regression, Support Vector Machine, and Naïve Bayes, across the TF-IDF extraction.
Number of Sentences and Tokens per Class
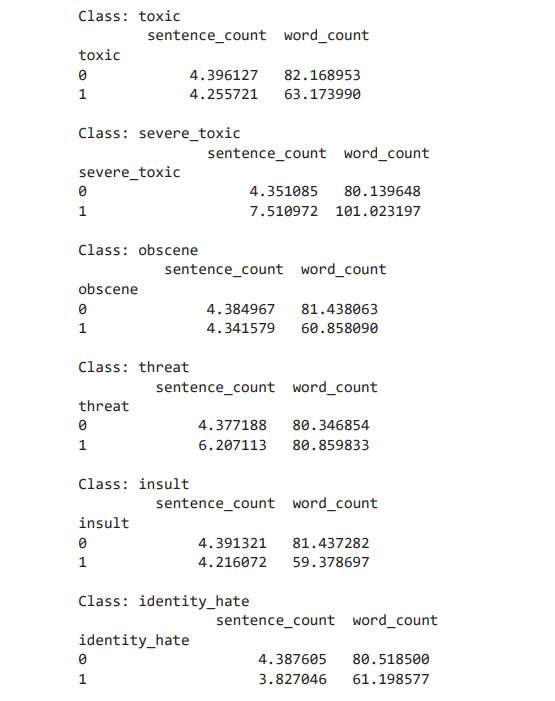
This section employed nltk to tokenize the words and sentences in the comment text column. The number of sentences and tokens for every class was also calculated (Figure 1)
Figure 1 The Average Sentence and Toke (Word) Counts for Comments in Various Categories
The figure above shows the average sentence and token (word) counts for comments classified under different toxicity categories. Comments labeled as 'severe_toxic' have notably higher averages, with approximately 7.51 sentences and 101.02 words, suggesting they tend to be longer and possibly more elaborate. In contrast, the 'toxic,' 'obscene,' 'threat,' 'insult,' and 'identity_hate' categories have fewer sentences and words on average, showing shorter comments. Interestingly, non-toxic comments (where the class is '0') largely have more words contrasted with the toxic ones, except in the 'threat' category, where the word count is slightly higher for toxic comments. These patterns might mean that severely toxic comments are more wordy, while other kinds of toxicity are expressed more concisely. It is also observable that the sentence count does not differ as widely across categories as the word count, which might show a similar sentence complexity across various toxicity levels.
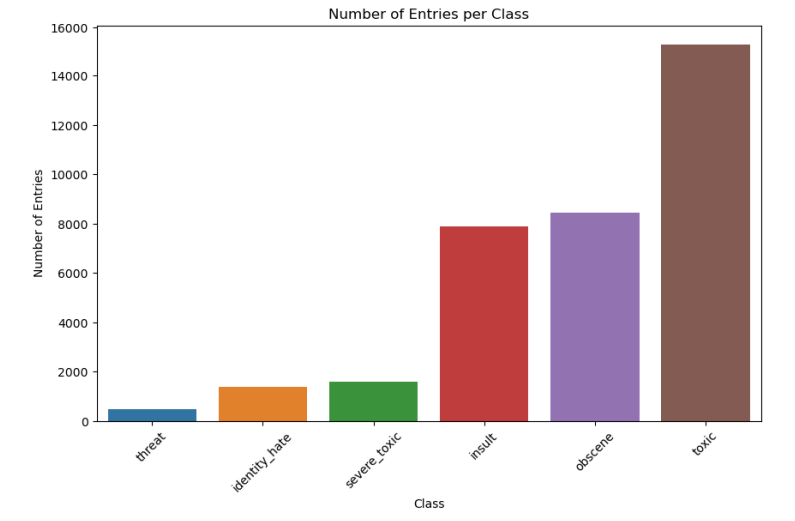
Figure 2 The class distribution of entries in the dataset
The bar chart in Figure 2 shows the class distribution of entries in the dataset, revealing a significant imbalance. The toxic class has the greatest number of entries, overriding all other categories, followed by obscene and insult classes with a moderate presence. In contrast, threat, identity_hate, and severe_toxic classes have relatively few entries, with "threat" being the least represented. This imbalance indicates that the dataset predominantly comprises comments labeled as 'toxic', which could influence model performance and necessitate rebalancing techniques for effective model training and validation.
Three ML learning algorithms were selected: Logistic Regression, Support Vector Machine, and Naïve Bayes. However, the logistic regression model was the one that completed the training successfully. Its performance is captured below.
Figure 3 Logistic Regression Performance
The performance metrics of the Logistic regression were similar before and after applying TF-IDF, with only slight variations. Accuracy dropped marginally by 0.0013, and the F1-score saw a minor drop of 0.0045 (Figure 4), indicating a slight drop in the balance between precision and recall. Recall improved slightly by 0.0013, suggesting a marginal rise in the model's ability to find all the relevant instances. Precision saw a more significant decrease of 0.0207, indicating that the model's predictions became less precise after TF-IDF (Liu et al., 2018; Zhuohao et al., 2022). The AUC decreased by 0.0013, which is negligible and suggests the model's discriminative ability is almost unchanged.
Figure 4 Logistic Regression Performance after applying TF-IDF
The feature extraction method change to TF-IDF did not significantly impact the model's performance, suggesting that the Logistic Regression model is relatively robust to these changes in feature extraction methodology.
References
Dablain, D., Jacobson, K.N., Bellinger, C., and Chawla, N. V. (2023). Understanding CNN fragility when learning with imbalanced data. Mach Learn. https://doi.org/10.1007/s10994-023-063269
Liu, Q., Wang, J., Zhang, D., Yang, Y., and Wang, N. (2018). Text features extraction based on TF-IDF associating semantic. 2018 IEEE 4th International Conference on Computer and Communications (ICCC), Chengdu, China, 2018, pp. 2338-2343, Doi: 10.1109/CompComm.2018.8780663.
Risch, J., and Krestel, R. (2020). Toxic comment detection in online discussions, in; Agarwal, B., Nayak, R., Mittal, and Patnaik, S. (eds). Deep-learning-based approaches for sentiment analysis: Springer, pp. 85-109.
Zhuohao, W., Dong, W., & Qing, L. (2021). Keyword Extraction from Scientific Research Projects Based on SRP-TF-IDF. Chinese Journal of Electronics, 30(4), 652-657. https://doi.org/10.1049/cje.2021.05.007
RNNs are one of the most useful neural network architectures for solving various NLP problems.
Compare and contrast the application of different RNN architectures for solving various NLP problems.
Compare and contrast supervised and unsupervised machine learning methods in general, whilst making specific reference to at least two ML modelling techniques in each of the two broad classes. Your comparison should highlight strengths, weaknesses, and challenges for each of the ML modelling techniques mentioned in your post.
Draw up structured criteria that can be used in determining the most appropriate ML approach for developing a machine learning solution to a particular problem.
Post
What I truly cherish is how clearly you have explained the concept of one-to-many and many-to-one RNN architectures detailed in the text about image captioning and sentiment classification. The first two examples showcase the ability of RNNs to process sequential data and to produce output that is meaningful. Image captioning based on the use of LSTM is viable, as this technique helps in addressing the problem of caption generation of variable length that exists due to the complexity of the input image (Smagulova and James, 2019).
Indeed, you were quite right that RNNs are accompanied by some challenges, e.g., vanishing and exploding gradients. An overwhelming gradient is the obvious reason for obstructed vision and this is confirmed with your image captioning example. This particular challenge might impair the model greatly, in terms of accurately define and explain the content in the image (Dadoun and Troncy, 2020). The association between sentiment categorization and grammatical faults which arise due to an explosion of gradients clearly reveals the need for attention paid to the optimal parameter selection and gradients-related problems in NLP systems. It becomes important for the providers to be aware about these pitfalls and usability of techniques like gradient clipping for preventing them.
Besides the challenge you mentioned about the training process of RNNs also entails high calculation cost which is another problem. Training RNNs is a quite computer-extensive procedure, particularly with vast datasets, and is a persistent issue of balancing between complexity of model and computational efficiency (Gori et al., 2009). Overall, this posts a detailed account of how the major types of RNN architectures are put to use in the NLP domain and the commonly encountered problems. It can serve as the foundation for the dialog about these problems and can help to enhance the resistance of RNN systems in practical applications.
References
Dadoun, A. and Troncy, R. (2020). Many-to-one Recurrent Neural Network for Session-based Recommendation. [online] arXiv.org. doi:https://doi.org/10.48550/arXiv.2008.11136.
Gori, M., Hammer, B., Hitzler, P. and Palm, G. (2009). Perspectives and challenges for recurrent neural network training. Logic Journal of the IGPL, 18(5), pp.617–619. doi:https://doi.org/10.1093/jigpal/jzp042.
Smagulova, K. and James, A.P. (2019). A survey on LSTM memristive neural network architectures and applications. The European Physical Journal Special Topics, 228(10), pp.2313–2324. doi:https://doi.org/10.1140/epjst/e2019-900046-x.
Summary
The approach concentrated mainly on the one-to-many and many-to-one RNN models, and the discussions resulted in priceless guides that have narrowed down and increased my knowledge base on their use cases.
The first conclusion that I managed to draw from discussions was that the architecture of RNN should be the most appropriate depending on the NLP task. The many-to-one RNN model that I have identified early is overwhelmingly exemplified as being the best choice for the task of sentiment analysis. Peers specifically drew the attention of processing sequence of words, giving a single sentiment value, especially for applying in movie review sentiment classification (Tembhurne & Diwan, 2020). Also, the class conversations bring into the shadow the intricacies associated with the many-to-one model, including the problem of vanishing gradient. The addition of Long Short-Term Memory (LSTM) or Gated Recurrent Unit (GRU) cells as a method to solve the problem of long-term dependencies and handle information flow was stressed as a significant approach to overcome these challenges (Liu et al., 2024).
On the other hand, the one-to-many RNN architecture with narrow focus on such tasks as language generation and text summary attracted lots of attention. In this situation the example of image captioning, via which the model generates a textual description of an image, was highlighted as a particularly important application of this architecture (Hu et al., 2022). On the other hand, the stumbling block of the exploding gradient remains relevant for one-to-many RNNs and is observed mostly during the initial phase of training. Techniques such as gradient clipping, prudent initializing of parameters, the use of regularization techniques that dropout to tackle these problems. The addition of sophisticated optimization algorithms such as RMSProp or Adam not only increases the ability to smooth the training but also provides a stable mode.
Alongside that, the discussions time allowed me to gain more knowledge on other strategies to strengthen the RNN models in NLP tasks. Techniques such as group normalization as well as slope clipping were suggested to help in achieving stability of training, calculation of robust gradients, and smooth convergences (S et al., 2021). The underlying idea that parameter initialization, regularization, as well as the model's architecture modification can lead to the success in RNN applications emphasized the collaborative approach to problem-solving.
Reviewing the classes' discussions convinced me on the essentiality of RNNs in NLP while also giving me a fascinating comprehension of the different structures' complexities. The insight I gathered made me revisit my strategy, and that is what made me see the necessity of being selective at the time of choosing RNN models and using diverse techniques to address particular problems. The versatile nature of the group discussions where case studies and diverse opinions are encouraged, made the learning experience more colorful and the comprehension of the application of RNN in NLP more broad.
References
Hu, H., Zhu, X., Zhou, F., Wu, W., Hu, R. Q., & Zhu, H. (2022). One-to-Many Semantic Communication Systems: Design, Implementation, Performance Evaluation. IEEE Communications Letters, 1–1. https://doi.org/10.1109/lcomm.2022.3203984
Liu, X., Li, Z., Tang, Z., Zhang, X., & Wang, H. (2024). Application of Artificial Intelligence Technology in Electromechanical Information Security Situation Awareness System. Scalable Computing: Practice and Experience, 25(1), 127–136. https://doi.org/10.12694/scpe.v25i1.2280
Tembhurne, J. V., & Diwan, T. (2020). Sentiment analysis in textual, visual and multimodal inputs using recurrent neural networks. Multimedia Tools and Applications. https://doi.org/10.1007/s11042-020-10037-x
Implement a seq-2-seq model with and without attention mechanism for developing a generative chatbot using one of the datasets listed below.
Datasets to be utilized for developing chatbots
Question Answer Datasets
The WikiQA Corpus was made publicly available in 2015, and has been updated several times since its inception. It contains different sets of question and sentence pairs that were originally collected.
Question-Answer Dataset. This chatbot dataset was designed for use in Academic research, and features Wikipedia articles alongside manually-generated factoid questions that come from them. It also features manually-generated answers to the aforementioned questions.
Customer Support Datasets
Ubuntu Dialogue Corpus: Consisting of almost one million two person conversations that have each been taken from the Ubuntu chat logs, this dataset is perfect for training a chatbot. It contains 930,000 dialogues spanning 100,000,000 words.
Tasks
Develop chatbot based on the following models using one of the chosen datasets.
Seq-2-seq model without attention
Seq-2-seq model with attention – Can use either Bahdanau or Luong Attention mechanism in the project
Carry out necessary pre-processing tasks to prepare the data
Split the dataset into appropriate Train/Validation/Test sets
Use the Validation set to train the model
Evaluate model on Test set
Assess the performance of the two models in terms of their accuracy or BLEU score
Manually evaluate (on a smaller subset), answers generated by chatbot
The report presents a chatbot built using a sequence-to-sequence long short-term memory (LSTM) model using WikiQA question-answer data (Download Microsoft Research WikiQA Corpus from Official Microsoft Download Center, no date). The report includes preprocessing, model design without attention (WoA) and with attention (WA) and a result and discussion section evaluating the model using Bilingual Evaluation Understudy (BLEU) and manual assessment of information retrieval.
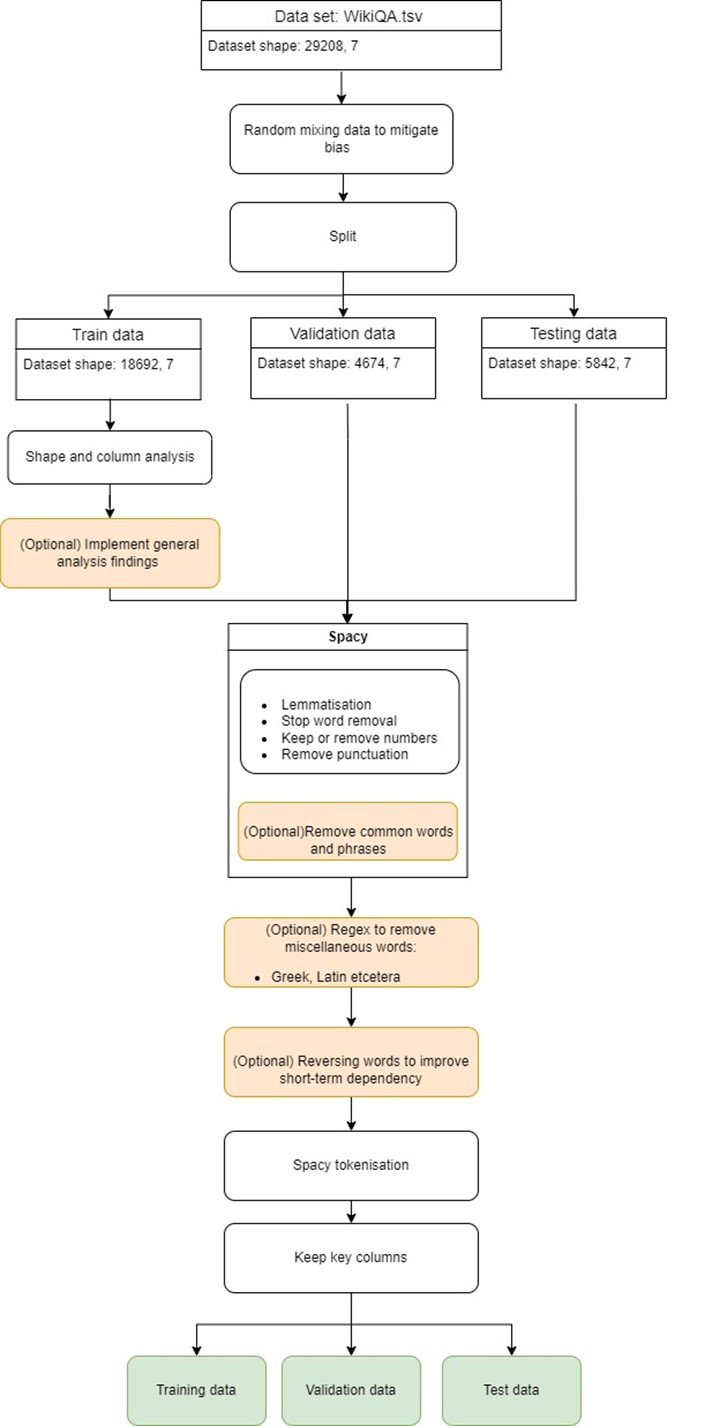
Figure 1. Analysis flowchart
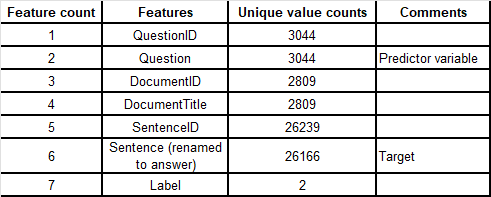
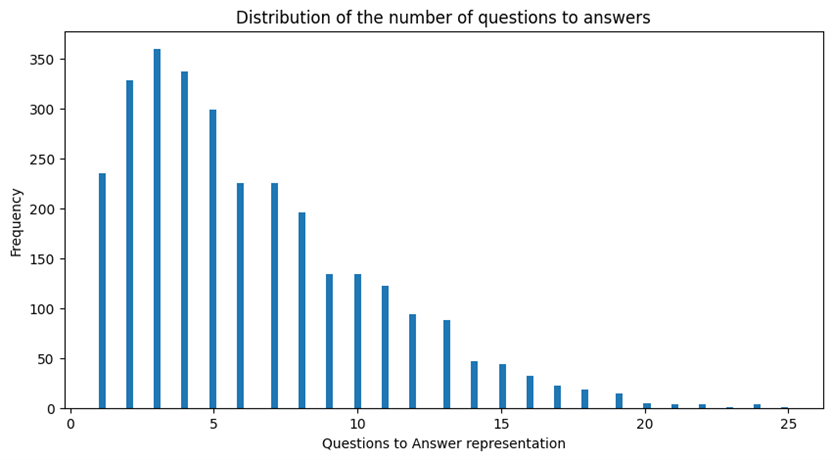
WikiQA.tsv was chosen as it was the original dataset, allowing for a ground-up analysis mitigating issues in the other datasets. The analysis focused on two key features: ques-tion and sentence (called answer). The former was the predictor, and the latter was the target. The findings show a directional one-to-many relationship (Q→A), as questions can have many answers. However, the data presents it as a one-to-one relationship due to the repetition of questions.
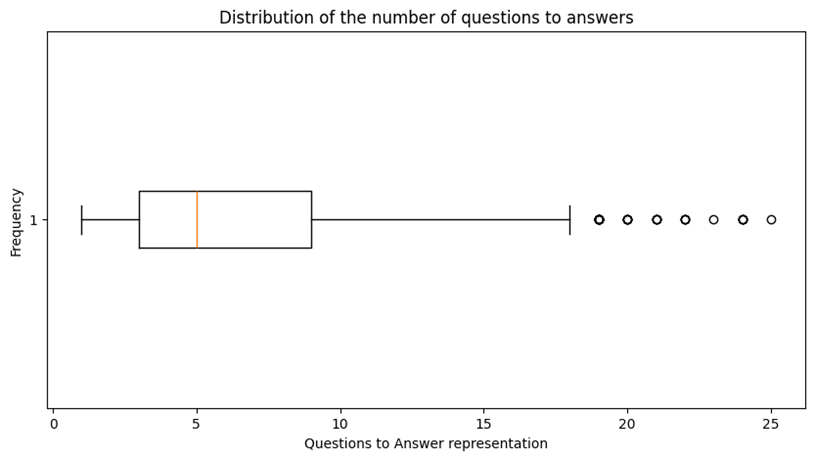
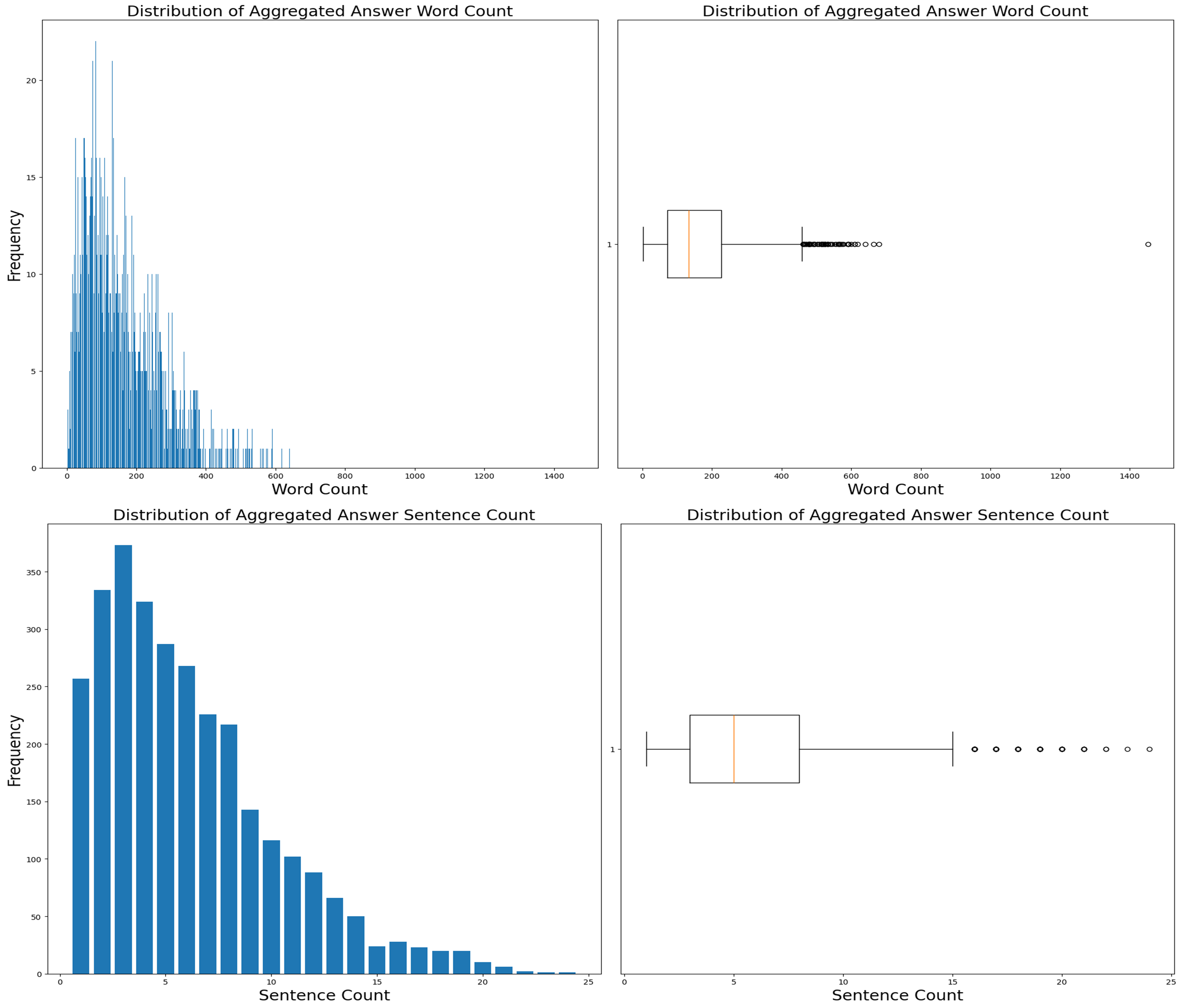
Q→A count has a right-tailed distribution (Figures 7 and Table 3 in the Appendix) and removing outliers could help the generalisability of the model if the test data is centred around the median.
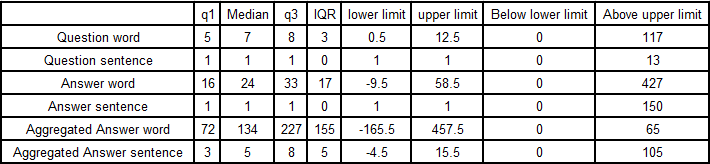
Table 1 – The WikiQA features and counts.
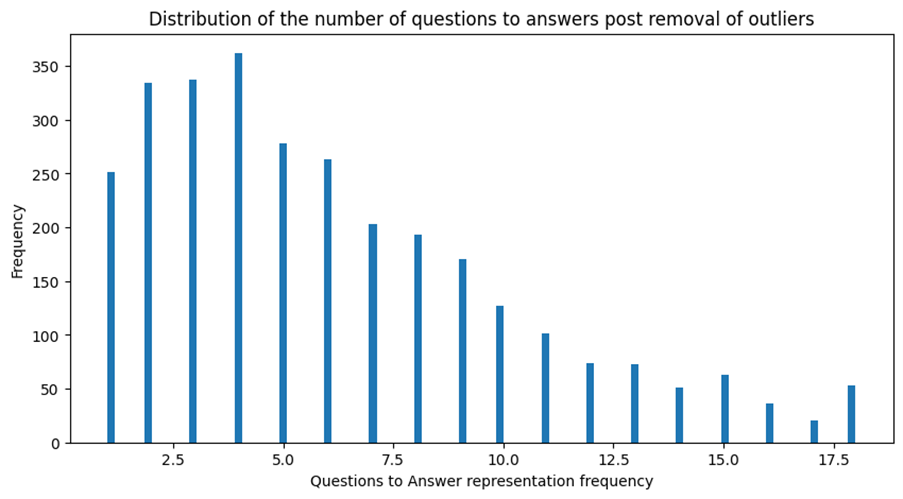
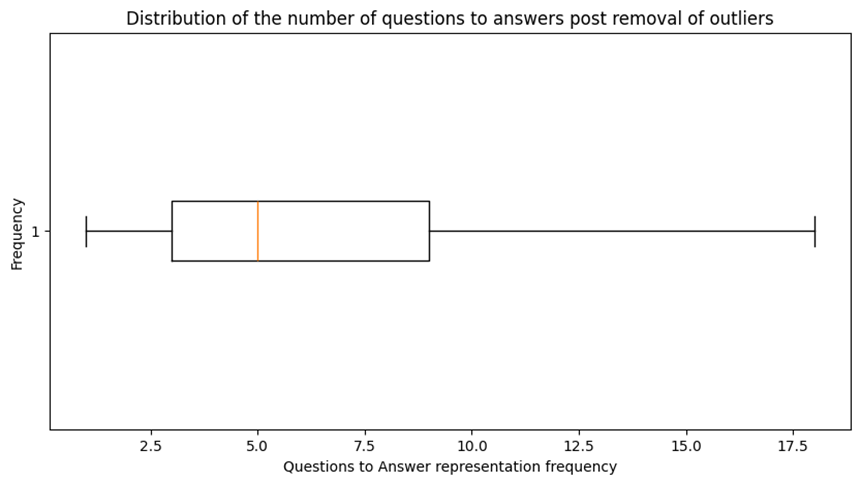
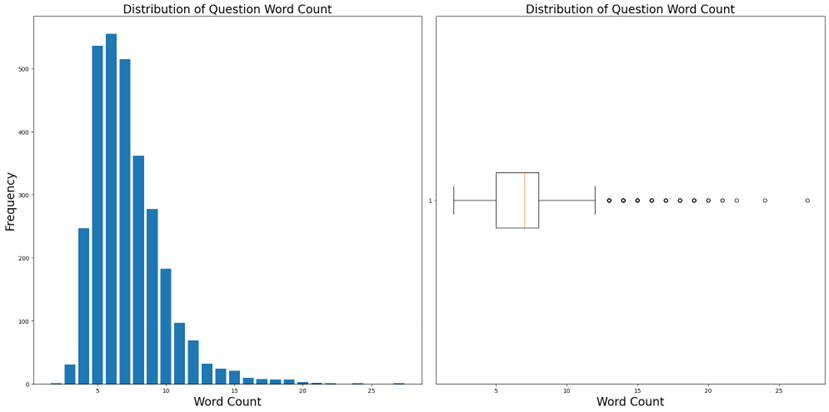
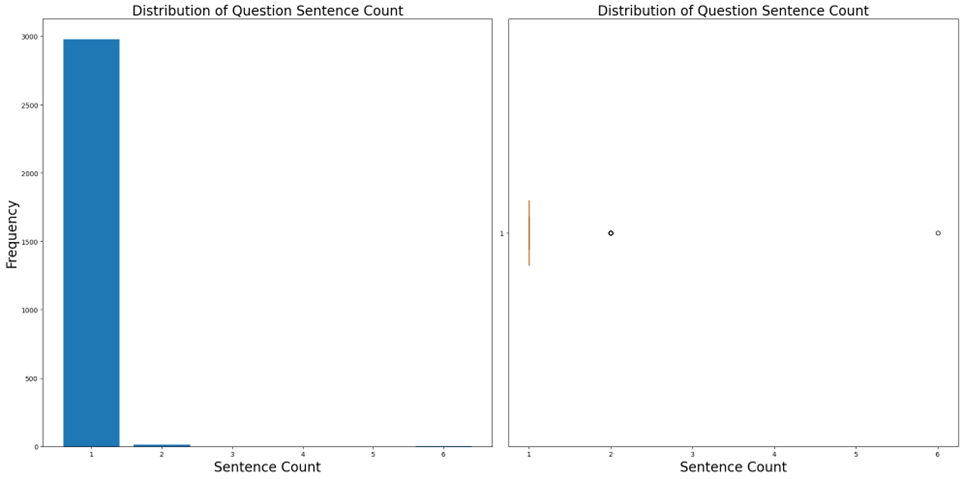
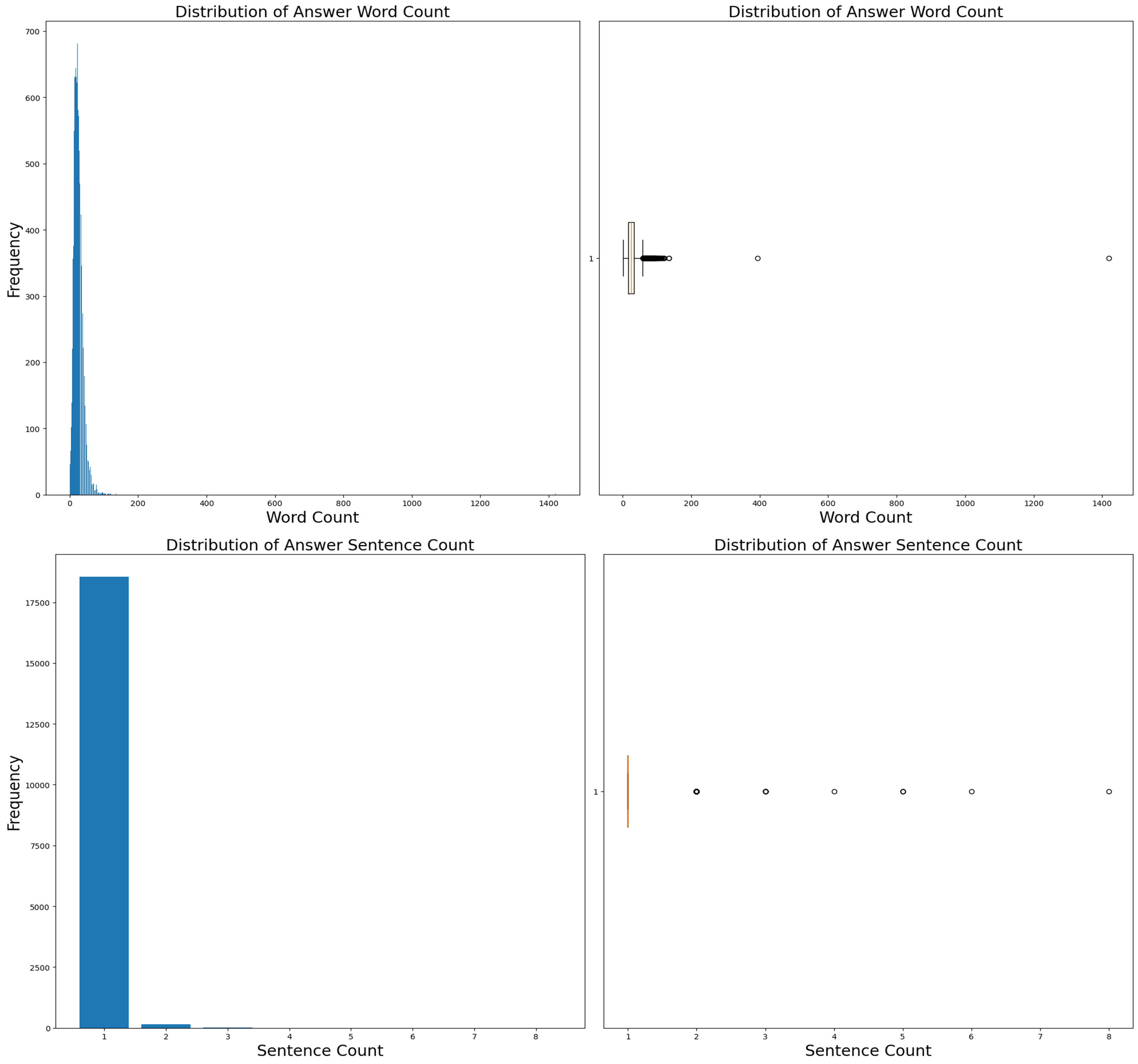
Word and sentence analysis on the key features showed a right-tailed distribution with outliers above the upper limit (Figures 8,9 and 10 in the appendix). This distribution could make the model adept at handling shorter data sequences, and removing outliers may enhance this characteristic, but doing so might affect its performance with longer ones. Hence, the decision was made not to remove these outliers.
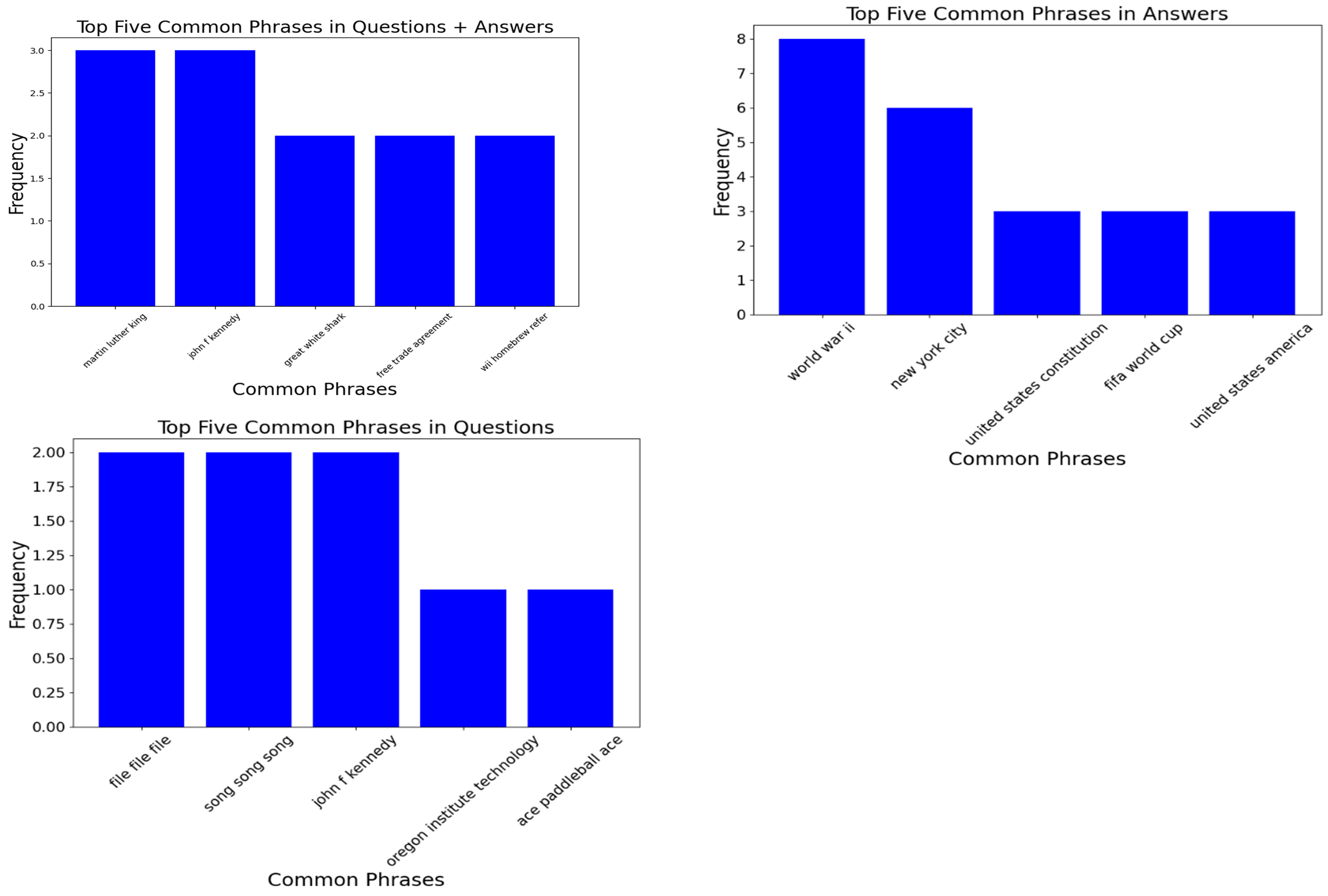
The relationships between Q→A were further evaluated to identify non-distinct words and phrases that cross question, answer, and question and answer pairs, providing little dis-criminative value. The process involved grouping on DocumentTitle, as this feature can include many related Q→A, allowing for intra-dependencies on related topics and thus strengthening intra-topic relationships by weakening inter-topic ones, reducing noise and promoting appropriate patterns. However, non-distinct words and phrases that cross groupings as proportion are tiny but may subtly aid the model in distinguishing Q→A.
Figure 2. Key relationships.
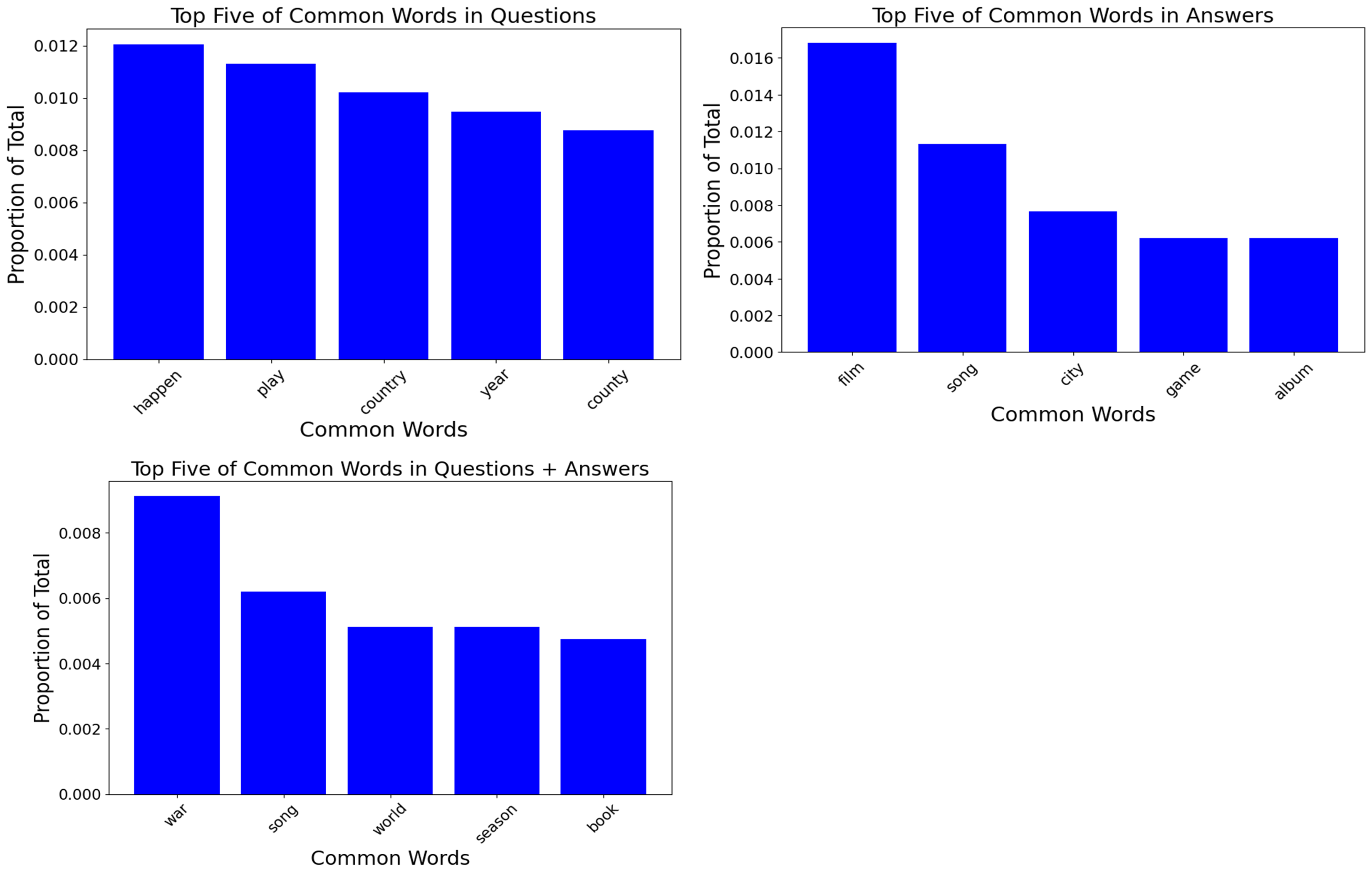
Figure 3. Top 5 words in Q→A relating to DocumentTitle. Common phrases are graphed in figure 11 of the appendix.
The pipeline is designed with optional steps to implement analytical findings gradually. It focused on mitigating data leakage, promoting relevant associations and cleaning the data as per the advice detailed in Silva (2023) and Kommareddy (2022). Hence, text was lemmatised, stop words, punctuation and non-word characters were removed. However, numerics were kept, as Q→A contained dates that may impart value. Hence, the pipeline has optional steps to promote careful implementation, mitigating overprocessing and maintaining data integrity.
Figure 4. Preprocessing pipeline.
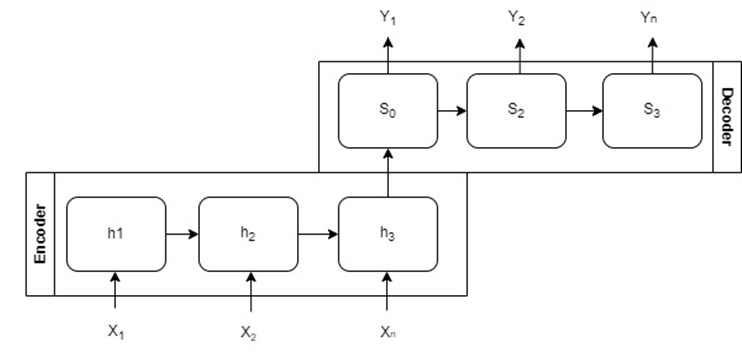
Figure 5. WoA model.
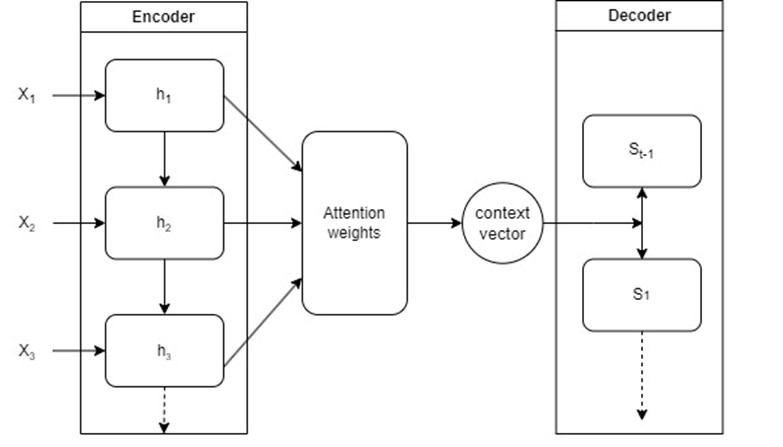
Figure 6. WA model.
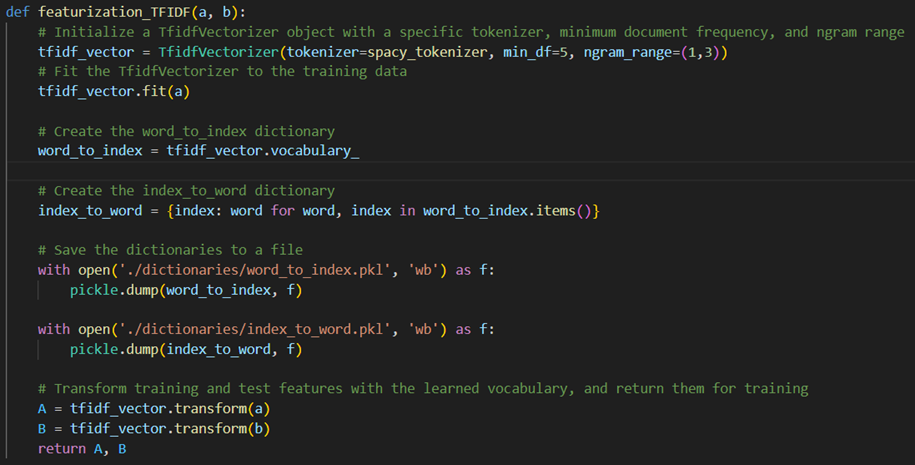
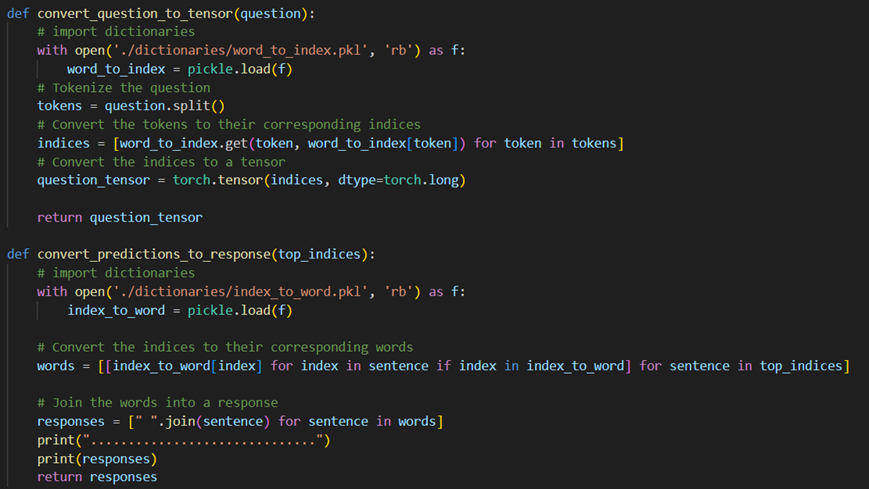
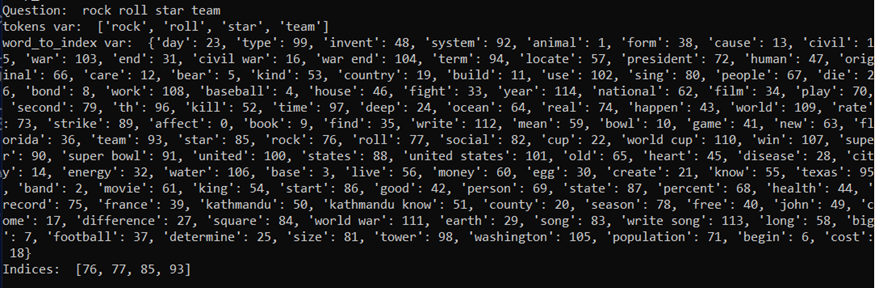
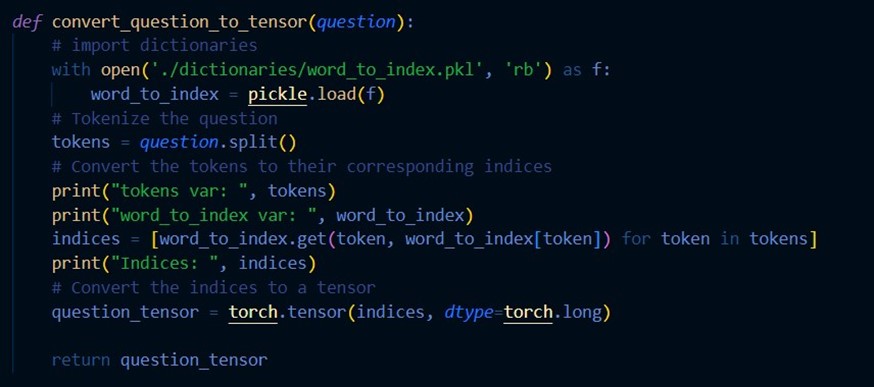
A featurisation method was used to extract text data with the Term Frequency-Inverse Document Frequency (TF-IDF) method (figure 12 of the appendix). It learns the vocabu-lary dictionary of all tokens in the raw document and creates word_to_index and in-dex_to_word pickle files for mapping purposes. The generated document-term matrices are then returned. The function convert_question_to_tensor tokenises the input from the users, converting these tokens to their corresponding indices, which are converted to a tensor (figure 12 of the appendix). Additionally, convert_predictions_to_response gets indices of words with the highest probability for each prediction and converts them to their corresponding words, joining the words to generate a response (figure 13 of the appendix).
The encoder composed of LSTM units takes a sequence of word indices as input and embeds them into a continuous space (Dhote, 2020). The encoder processes the se-quence and outputs a final hidden state, capturing the semantic information of the input sequence in a fixed-length vector (Moses, 2021). A decoder then uses this hidden state to predict an output sequence (Moses, 2021). The dropout layer prevents overfitting dur-ing training (Srivastava et al., 2014). The init_hidden method is used to initialise the hid-den state of the LSTM at the start of each sequence.
The decoder composed of LSTM units takes the final state of the encoder as the initial input from the encoder, embedding the word representation in a continuous space (Mo-ses, 2021). The decoder processes the sequence and outputs a sequence of hidden states. Each hidden state is then passed through a linear layer to produce a distribution over the output vocabulary for each word in the output sequence. The dropout layer pre-vents overfitting during training (Srivastava et al., 2014).
The attention mechanism allows the model to focus on different parts of the input se-quence for each step of the output sequence, which can be especially useful for cases where the sentence is long (Maji, 2021). The forward method takes in the inputs, the hid-den state, and the encoder outputs, and returns the output after applying the attention mechanism and passing through the LSTM.
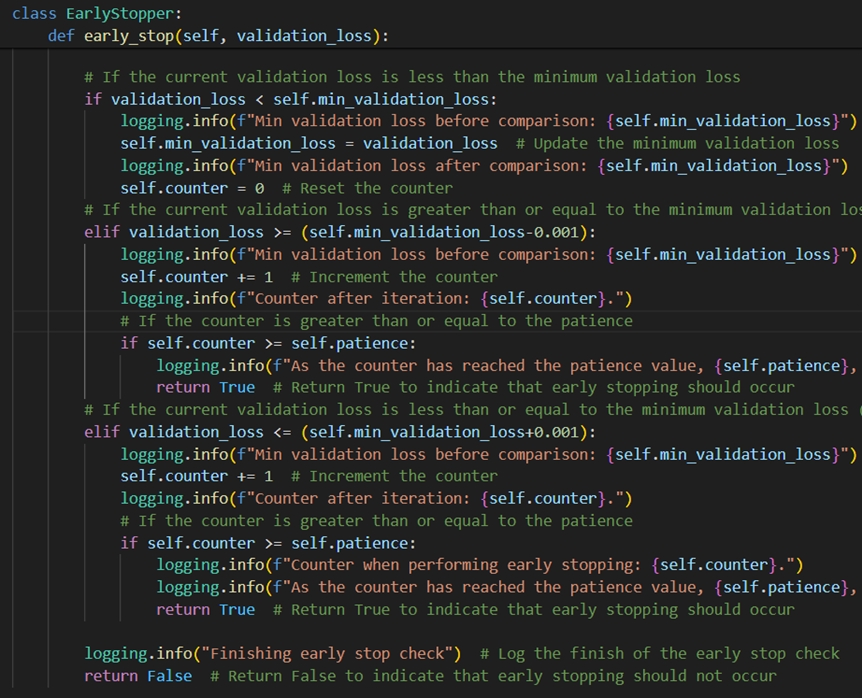
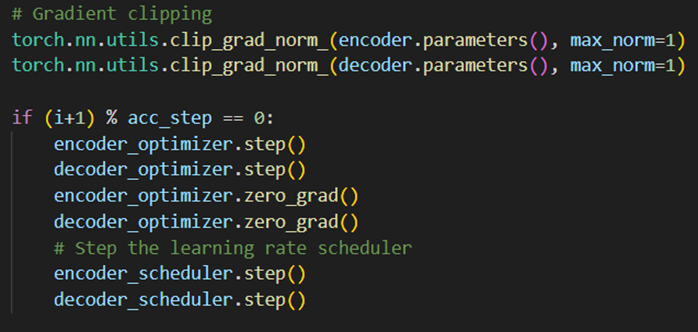
Gradient clipping was implemented to prevent exploding gradients by thresholding them to a maximum value to stabilise the training and improve the network’s performance. Ear-ly stopping is a form of regularisation to stop training if the average loss is not improv-ing, which is applied to avoid overfitting (Figure 16 in Appendix). The learning rate scheduler aims to reduce the value after a predetermined number of steps. Gradient ac-cumulation technique was used to handle cases when large models cannot fit into memory. It computes the gradients over several batches and then performs the update of the optimisers (Figure 17 in Appendix). The components implemented allowed the model to train more effectively, even with limited memory. However, these improvements may need more training steps as the model updates less often.
Two models were built, a WoA and a WA, and the evaluation metric used was BLEU, which compares the generated answer from the model against the reference answer for a given question using a score between zero and one as a rating (Mulani, 2021). Zero indi-cates the model performed poorly, while one is a perfect score.
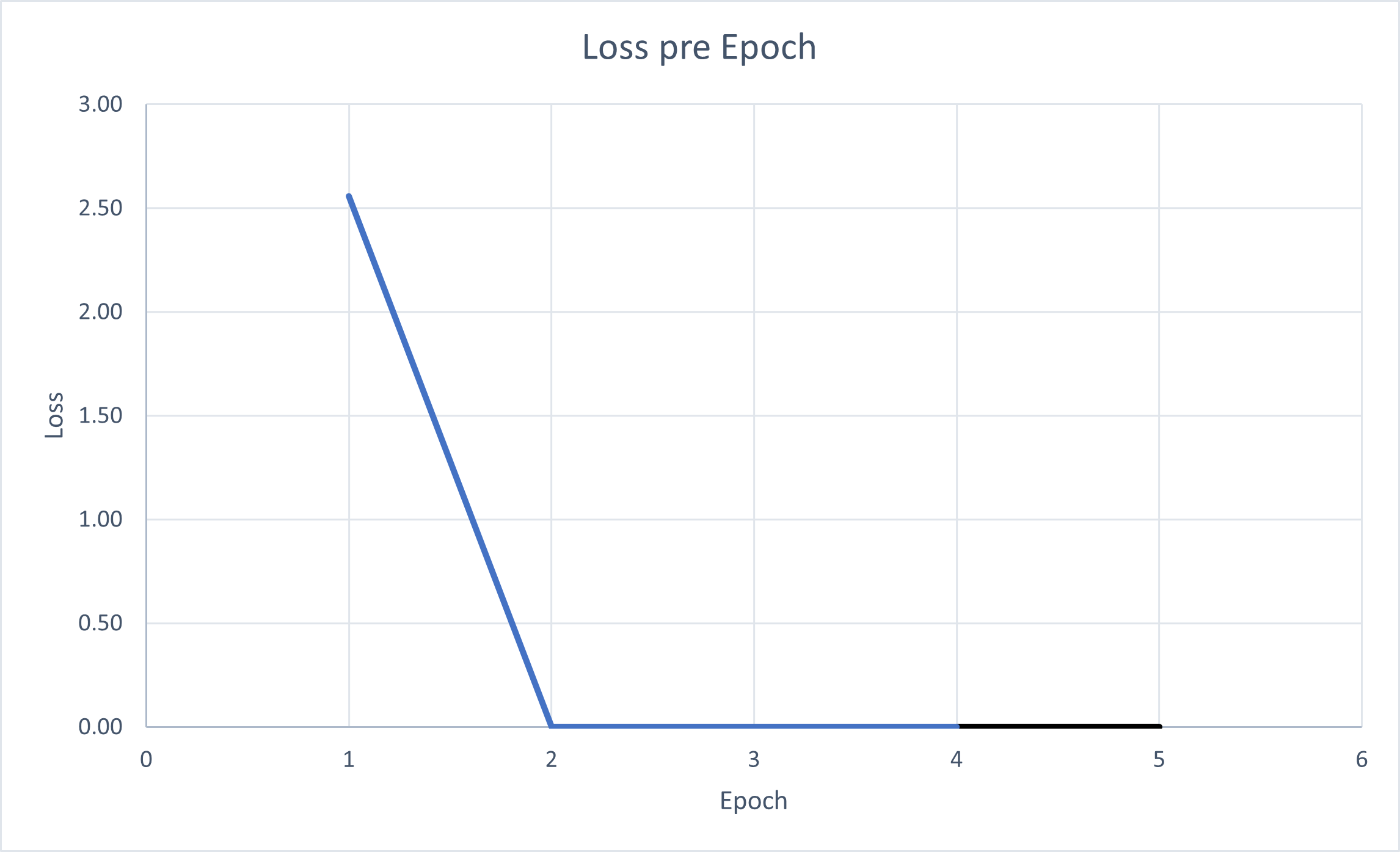
Figure 7. Loss over epoch.
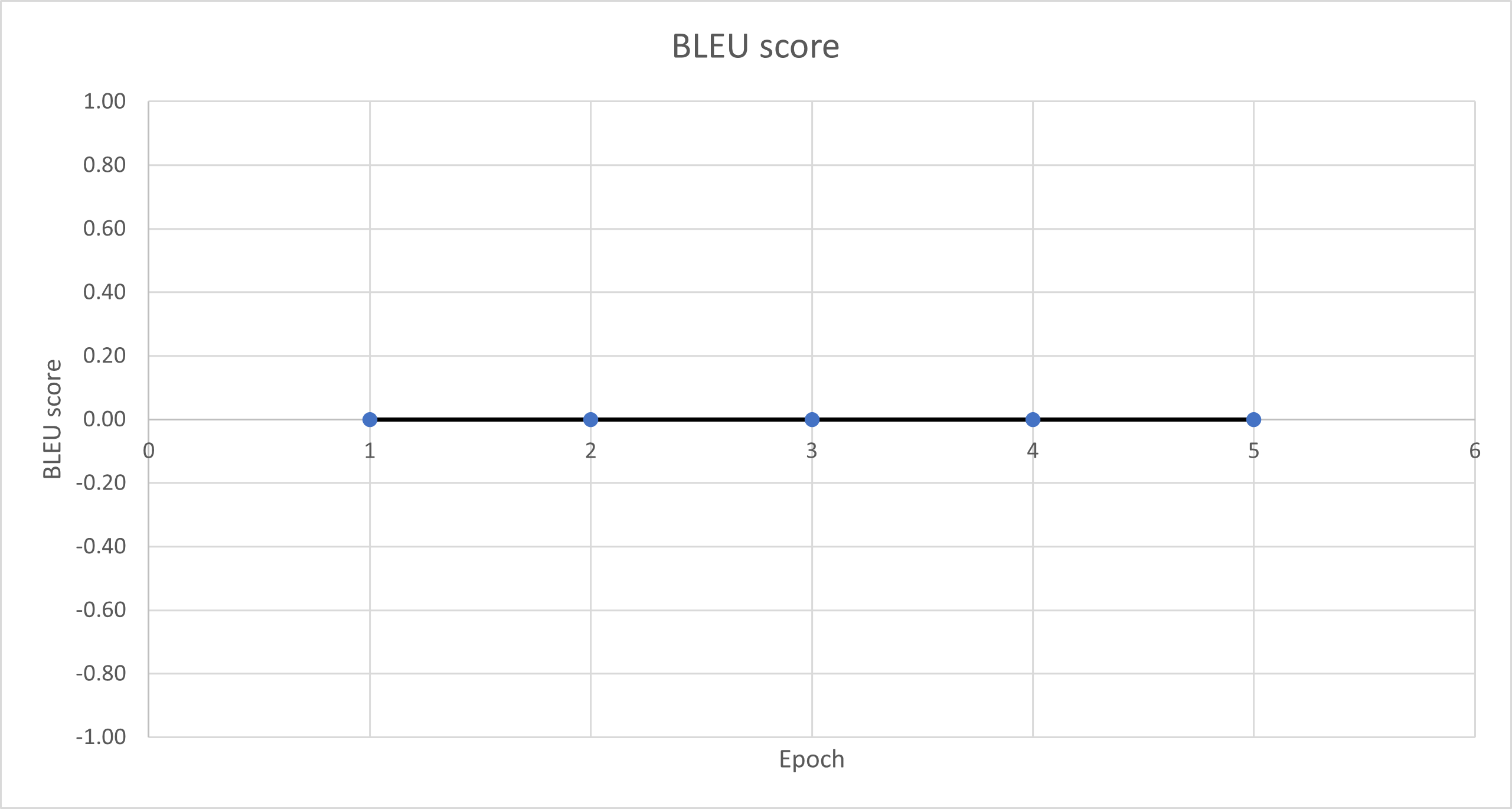
Figure 8. BLEU over Epoch
The WoA model has an impressive loss after a single epoch, dropping to zero. This shows that its predicted output is close to the ground truth (Gomede, 2023). However, the sudden drop from 2.5 to zero is strange and could suggest overfitting (Holbrook R, 2023). Additionally, the BLEU results support this assumption, meaning that the output answer from the model does not overlap with the reference answer, suggesting that learn-ing was perturbed.
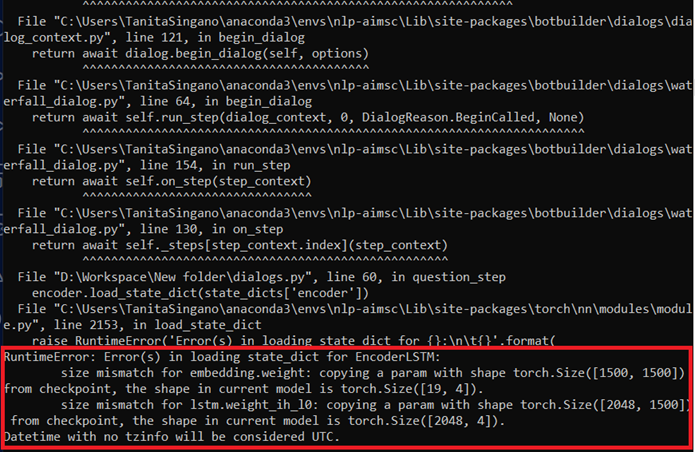
Unfortunately, results for the WA model could not be attained. This was due to a persis-tent matrix error associated with the tensor input into the softmax function.
Despite the implementation of components designed to enhance the efficiency and per-formance of model training, numerous challenges were encountered. Notably, the ab-sence of a data preprocessing step to incorporate start and end-of-sentence tags was a significant oversight. Furthermore, we consistently encountered issues related to dimen-sion mismatches during the computation of attention weights and the execution of vector and matrix transformations (Figure 18 in Appendix). Moreover, due to the constraints of computational resources, only a fraction of the available data was utilised to train and evaluate the models.
The chatbot’s ability to respond accurately to user questions relies on a combination of trained models and dictionaries. However, challenges related to data dimensions impact-ed the performance of generating responses. The Bot Framework SDK (JonathanFingold, 2022) provides a modular and extensible software development toolkit (SDK) for building bots. Owing to the mentioned challenges, the chatbot was restricted to employing a se-quence-to-sequence model without attention mechanisms. This resulted in poor perfor-mance, which can be attributed to the insufficient data provided during the training pipe-line.
By including start and end-of-sentence tags at the beginning of each question and an-swer entry, the tokens would have informed the model of the association between each question and answer entry, creating a distinction between respective questions and an-swers, preventing blending between entries and enhancing performance (Maji, 2020).
Assessing the problematic computation of attention weights and vector and matrix trans-formations should rectify the WA model's issues.
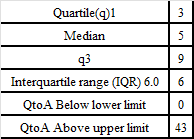
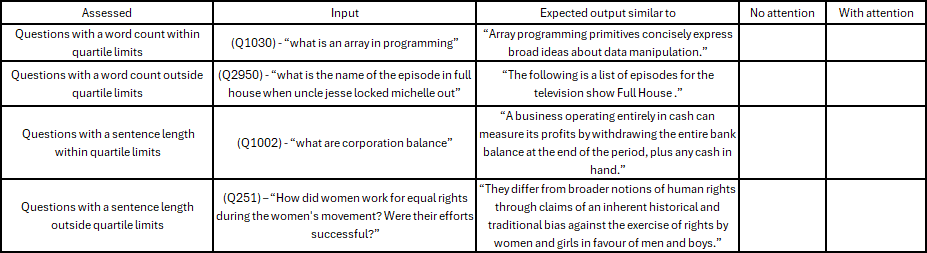
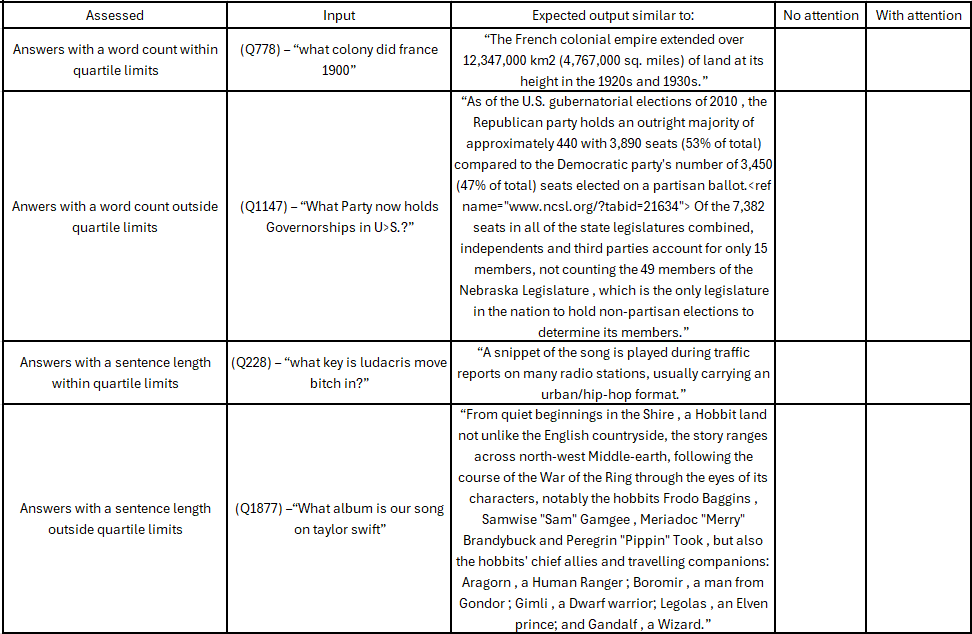
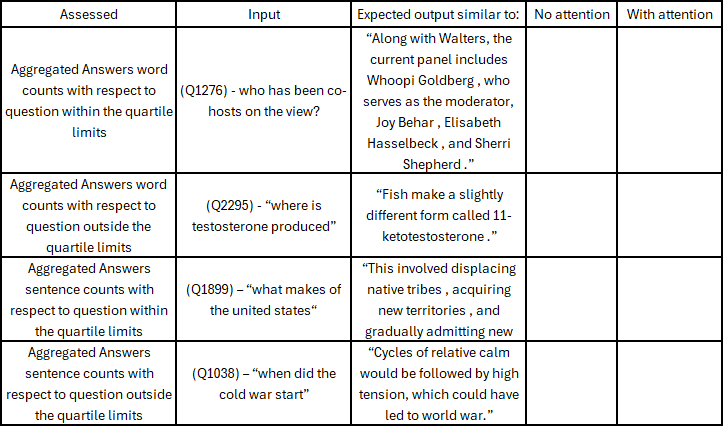
Given the implementation of these resolutions, the chatbot would then be evaluated manually for information retrieval, which is the ability of models to fetch relevant infor-mation in response to user inputs (Peras, 2018). It can be based on quartile ranges found in the analysis (table 6,7,8).
Though the models did not perform as intended, they provide a solid foundation for re-finement. Thus, the missing end-of-sentence tags are included in the preprocessing pipe-line, and the issue with the matrix transformation for the WA model is corrected. There is confidence that the chatbot will perform as intended.
Kommareddy, N. J. (2022) 'Data Preprocessing Framework for Supervised Machine Learning', International Journal of Research in Engineering and Science (IJRES), 10(11), pp. 304-308.
Kotsiantis, S. B., Kanellopoulos, D. and Pintelas, P. E. (2006) 'Data preprocessing for supervised leaning', International journal of computer science, 1(2), pp. 111-117.
Sojasingarayar, A. (2020) 'Seq2seq ai chatbot with attention mechanism', arXiv preprint arXiv:2006.02767.
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I. and Salakhutdinov, R. (2014) 'Dropout: a simple way to prevent neural networks from overfitting', The journal of ma-chine learning research, 15(1), pp. 1929-1958
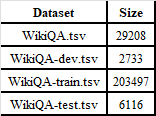
Table 2 – The datasets. WikiQA.tsv was chosen.
Table 3 – The WikiQA features and counts.
Figure 9. A series of graphs showing that the QA distribution is right-tailed and the impact of removing outliers.
Table 4 – Total number of words and sentences.
Table 5 – Quartile ranges for word and answer counts.
Figure 10. A series of graphs showing word and sentence counts for Questions.
Figure 11. A series of graphs showing that words and sentence counts are right-tailed for answers.
Figure 12. A series of graphs showing that words and sentence counts are right-tailed given Q→A.
Figure 13. Common phrases in Q→A concerning DocumentTitle.
Figure 14. TF-IDF vectoriser implementation
Figure 15. Used to generate a response for the user.
Figure 16. Early stopping
Figure 17. Gradient clippings
Figure 18. TF-IDF.
Figure 19. Embedding dimensions in red.
Figure 20. Questions to tensor.
Table 6 – Question words and sentence counts.
Table 7 – Answers words and sentence counts.
Table 8 – Q→A representative. Assessing no attention against with attention.