Explore and discuss the nature of Intelligent systems, their characteristics, and applications.
Understand how rule-based expert systems work, their techniques, how they are represented and their notation.
Analyse how reasoning can be implemented on intelligent systems, evaluating uncertainty, analysing different structures (emphasising genetic algorithms), and defining rules.
Study how different type of systems and logics are implemented in various applications.
Topic
Intelligent systems are advanced computing systems that can perceive, understand and respond to the world around them. They mimic human reasoning skills, human competence, and human expertise taking many forms, from automated vacuum robots to personalized recommender systems, from self-driving cars to virtual voice assistants . Intelligent systems have been fulfilling a growing number of roles in our modern lives with applications in an ever-increasing number of domains.
Focus on a specific domain where intelligent systems play an important role already
Describe what makes the use of intelligent systems preferable to the use of conventional computer systems within the chosen domain
Discuss the challenges that intelligent systems have been facing.
Select one example of an existing intelligent system and explain how it works.
Address the legal, social, and ethical impact of your chosen intelligent system
Post
Intelligent systems, powered by artificial intelligence (AI) and machine learning, have begun to revolutionize numerous domains, and healthcare is one such area where their impact has been significant (Obermeyer & Emanuel, 2016). The use of intelligent systems in healthcare is highly preferable to conventional computer systems due to its ability to process vast amounts of data, adapt to changing circumstances, and provide personalized, precise, and timely medical care (Topol, 2019). However, as with any technological advancement, there are notable challenges, including concerns about data privacy, accountability, and ethical considerations. In this discussion, we will delve into the domain of healthcare, focusing on intelligent systems' role, challenges they face, and an example of an existing system, along with its legal, social, and ethical implications.
The Preferability of Intelligent Systems in Healthcare
Intelligent systems in healthcare offer several advantages over conventional computer systems. These systems leverage advanced algorithms and machine learning models to process vast datasets, allowing for the detection of patterns and trends that would be impossible for human healthcare providers to identify (Rajkomar, Dean, & Kohane, 2019). Here are some key reasons for their preferability:
Personalized Medicine: Intelligent systems can analyze a patient's medical history, genetics, and other data to tailor treatment plans. This personalization enhances the effectiveness of treatments, reduces side effects, and improves patient outcomes.
Predictive Analytics: These systems can predict disease outbreaks, identify high-risk patients, and even forecast equipment maintenance needs, leading to more proactive healthcare delivery.
Efficiency and Speed: They can process medical records and clinical data faster than human professionals, reducing diagnosis and treatment times.
Continuous Learning: Intelligent systems can continuously learn from new data, medical research, and treatment outcomes, ensuring that medical decisions are based on the latest information.
Challenges Faced by Intelligent Systems in Healthcare
While intelligent systems hold immense promise, several challenges must be addressed:
Data Privacy and Security: The collection and storage of sensitive patient data raise concerns about privacy and the potential for data breaches.
Ethical Dilemmas: Decisions made by AI systems can have ethical implications, such as when to withdraw treatment or allocate resources in resource-constrained situations.
Bias and Fairness: Machine learning models may perpetuate biases present in the training data, leading to disparities in healthcare delivery.
Regulatory Hurdles: Compliance with healthcare regulations is a complex task, and many countries lack clear guidelines for AI in healthcare.
Human-AI Collaboration: Balancing the role of intelligent systems with human healthcare providers is an ongoing challenge. Maintaining the human touch in healthcare is essential.
Example of an Existing Intelligent System in Healthcare: IBM Watson for Oncology
IBM Watson for Oncology is an AI system designed to assist oncologists in developing personalized treatment plans for cancer patients. It leverages natural language processing and machine learning to analyze vast volumes of medical literature, clinical trial data, and patient records (Watson for Oncology). The system provides evidence-based treatment recommendations, considering the patient's medical history, genetics, and specific cancer subtype. Oncologists can use these recommendations as a reference, helping them make more informed decisions.
Legal, Social, and Ethical Impacts
Legal: The use of AI in healthcare raises legal concerns, including liability in the event of errors or misdiagnoses. Regulations and guidelines need to be adapted to accommodate AI systems.
Social: The introduction of intelligent systems can affect the roles of healthcare professionals, potentially leading to concerns about job displacement. However, it can also alleviate the burden on overworked healthcare staff.
Ethical: Ethical issues abound in healthcare AI, such as transparency of AI decision-making, informed consent for patients, and ensuring that algorithms do not exacerbate existing health disparities.
In conclusion, intelligent systems in healthcare offer unparalleled advantages, such as personalization, predictive analytics, and increased efficiency. However, these systems also confront challenges concerning data privacy, bias, and ethical concerns. IBM Watson for Oncology serves as a notable example of AI's potential in healthcare. Striking a balance between reaping the benefits and addressing these challenges is pivotal as intelligent systems continue to transform the healthcare landscape.
References
Obermeyer, Z., & Emanuel, E. J. (2016). Predicting the future—Big data, machine learning, and clinical medicine. New England Journal of Medicine, 375(13), 1216-1219.
Topol, E. J. (2019). High-performance medicine: The convergence of human and artificial intelligence. Nature Medicine, 25(1), 44-56.
Rajkomar, A., Dean, J., & Kohane, I. (2019). Machine learning in medicine. New England Journal of Medicine, 380(14), 1347-1358.
Watson for Oncology. (n.d.). IBM. [https://www.ibm.com/watson/oncology]
Summary
Intelligent systems are advanced machines that can help to perceive and respond to how the real world behaves or reacts. Therefore, the machines in inteligent systems have been designed to solve some of the challenges that exist in the world and even give conclusive reports on the provided data. This aligns with the provided technological advancements, where the notable challenges will be solved easily. According to Obermeyer and Emanuel (2016), healthcare is a sector that is evolving at a high rate, and they have been implementing intelligent systems for years. Intelligent systems have helped to process big data and ensure that the medical care offered is aligned with the new changes (Obermeyer & Emanuel, 2016). The main idea that was created in the discussion was that data-driven systems are designed to learn behaviours and that the interactions that are recorded will be used to build knowledge that will give conclusive results (Rajkomar et al., 2019). I received a response from Calum, where he pointed out that the role of intelligent systems is to diagnose and make a decision-based diagnosis that will give the right medications. The ideas raised by my peer also pointed out that, at times, human medical practitioners need to be present, as any errors could lead to misdiagnosis and wrong treatments (Alzghoul et al., 2014). In my understanding, the best example that can be implemented is the IMB Watson for Oncology, which enables the development of personalized treatments and the process of critical clinical data. Secondly, AI systems can help to decode medical images such as CT scans and ultrasounds, in which the right decisions will be made easily and accurately. Lastly, there is a need to consider the legal, social, and ethical impacts of intelligent systems, where there are regulations that have to be followed to ensure that patient data is well protected in the hospitals. The social aspects that can be considered are that health workers need systems that will help them solve medical problems, and this aids in reducing errors. Lastly, the ethical considerations are also tied to confidentiality, where medical reports have to be protected by the systems from exposure to unauthorized people.
References
Alzghoul, A., Backe, B., Löfstrand, M., Byström, A. and Liljedahl, B. (2014) 'Comparing a knowledge-based and a data-driven method in querying data streams for system fault detection: A hydraulic drive system application', Computers in industry, 65(8), pp.1126-1135. Available at: https://doi.org/10.1016/j.compind.2014.06.003
Rajkomar, A., Dean, J., & Kohane, I. (2019). Machine learning in medicine. New England Journal of Medicine, 380(14), 1347-1358.
Obermeyer, Z. and Emanuel, E.J., 2016. Predicting the future—big data, machine learning, and clinical medicine. The New England Journal of medicine, 375(13), p.1216.
Topic
Prolog is a programming language for artificial intelligence and language processing. Prolog's rule structure and inference strategy is adequate for many AI applications and the creation of intelligent systems. Prolog rules are used for knowledge representation, while Prolog's own built-in backward chaining inference engine is used to derive conclusions. Each rule has a goal and several sub-goals.
Prolog's inference engine either proves or disproves each goal (i.e. there is no uncertainty associated with the results).
In this assignment, you will work through the production of an individual software solution in Prolog that will result in a demonstrable software system. You will also produce a brief report that documents your software solution.
Scenario
The outbreak of the new virus disease was first detected in the city of Virusville in Virusland towards the end of the year 2519. One of the main concerns was that, as it was a completely new virus, there was no vaccine and no specific treatment for the disease, and thus the entire human population was potentially at risk to contract the infection. The virus was transmitted mainly when in close proximity with an infected person via small respiratory droplets (sneezing, coughing). The infected droplets could be either directly inhaled by someone else or land on surfaces that others could possibly come in contact with. On non-biological surfaces, the virus had the resilience to survive from several hours (copper, cardboard) up to a few days (plastic and stainless steel), depending on the surface's characteristics.
The time between exposure to the virus and onset of symptoms (the incubation period) was estimated to be between 1 and 14 days. The virus could be transmitted when people who were infected showed symptoms. There was also evidence suggesting that transmission occurred from a person that is infected even two days before the appearance of the first symptoms; however, uncertainties remain about the effect of transmission by persons showing no symptoms (being asymptomatic).
Symptoms of the virus varied in severity from being asymptomatic to having more than one symptom. The most common symptoms were fever, persistent dry cough, and tiredness. Less common symptoms were aches and pains, sore throat, diarrhoea, conjunctivitis, headache, anosmia/hyposmia (total/partial loss of sense of smell and taste), and running nose. Serious symptoms included difficulty breathing or shortness of breath, chest pain or feeling of chest pressure, loss of speech or movement. People with serious symptoms needed to seek immediate medical attention, proceeding with an initial assessment call (no contacts) to the doctor or health facility. People with mild symptoms had to manage their symptoms at home, without a doctor assessment. Elderly people (above 70 years old) and those with pre-existent health conditions (e.g. hypertension, diabetes, cardiovascular disease, chronic respiratory disease and cancer) were considered more at risk of developing severe symptoms. Males in these groups also appeared to be at a slightly higher risk than females. Most infected people developed mild to moderate illness and recovered without hospitalization.
Report
Chapter 1. INTRODUCTION
In response to the imperative need for efficient infection diagnosis, this research aimed to develop an expert system for viral infection diagnosis based on Prolog. Prolog provides an excellent framework for building logical decision-making procedures because of its rule-based programming architecture. When providing assessments and risk evaluations, the system considers symptoms, recent occurrences, and patient biodata (Wielemaker et al., 2012). This report helps in understanding the functioning of the expert system.
Chapter 2. SYSTEM DESIGN
2.1Symptoms and Risk Factors
The rules and information that specify the parameters for diagnosing viral infections form the foundation of the expert system (Enikeev, Burnashev, & Vakhitov, 2020). This range of symptoms, from the basic (fever, dry cough) to the more specialized (anosmia, loss of speech or movement), indicates a thorough awareness of common indications of diseas-es. A comprehensive diagnosis similarly depends on the identification of risk factors. De-mographic and health-related variables, including age (elderly), gender (male), and pre-existing medical disorders (hypertension, diabetes, cardiovascular disease), are all con-sidered significant by the system (Wielemaker et al., 2012).
2.2Diagnosis Rules
The key controller of the diagnostic process is the `possible_infection/1’ rule, which serves as the system's core. Sub-rules ‘has_symptoms/1’ for validating symptoms and `assess_risk/1’ for evaluating risk factors are defined by this rule. A close look at possi-ble_infection/1's logical progression exposes its careful handling of the diagnostic re-quirements. has_symptoms/1 validates symptoms by asking users to enter them, com-paring them to a preset list, and providing comments on known and unknown symptoms (Chen & Lin, 2021). The `symptom_case_insensitive/1’ case-insensitive matching predi-cate allows for greater flexibility in symptom detection. Similar to the symptom validation process, the `assess_risk/1’ rule asks users to provide risk factors and rigorously evalu-ates their validity based on predetermined standards (Enikeev, Burnashev, & Vakhitov, 2020). The case-insensitive matching predicate (factor_case_insensitive/1) ensures resil-ience in risk factor assessment.
2.3Interactive Input Handling
get_symptoms/1 and get_risk_factors/1. These predicates encourage user participation, which questions the user to help create a dynamic user experience by asking them to input symptoms and risk factors (Wielemaker et al., 2012).
2.4Case-Insensitive Matching
symptom_case_insensitive/1 and factor_case_insensitive/1. The system has case-insensitive matching for symptoms and risk factors since it understands that user input might differ depending on the situation (Enikeev, Burnashev, & Vakhitov, 2020). By re-ducing possible concerns stemming from changes in letter cases, these predicates guar-antee that the system stays resilient when receiving user input
2.5System Demonstration
Figure 1. Demo system execution example
For patient ID 1, the `possible_infection/1} rule is used in the system queries shown. When symptoms are entered, including fever, diarrhea, headaches, and chest pain, the algorithm accurately detects fever and the risk factor "elderly." In the second question, the proper identification of fever and the risk factor "diabetes" is achieved by addressing the symptoms of fever, headache, and chest pain. Both interactions demonstrate how well the system validates symptoms and risk factors, returning a {true} response when suggestive components meet the predetermined standards.
Chapter 3. CONCLUSIONS
In conclusion, the Prolog-driven expert system for infection diagnosis demonstrates a strong and dynamic diagnosis procedure. The examples of queries correctly identify key factors for a potential infection, demonstrating the system's competence in risk factor evaluation and symptom validation. Despite being simple, it shows how Prolog may be used to create rule-based expert systems and provide accurate results and recommen-dations. In the future, this system can be advanced to diagnose more complex challeng-es with increased precision.
References
Chen, K., & Lin, C. C. (2021, June). Design and Implementation of a SWI-Prolog-Based Expert System to Diagnose Anxiety Disorder. In Annual Conference of the Japanese Society for Artificial Intelligence (pp. 165–177). Cham: Springer International Publish-ing.
Enikeev, A. I., Burnashev, R. A., & Vakhitov, G. Z. (2020). Software tools and techniques for expert systems building. In Fourth International Congress on Information and Communication Technology: ICICT 2019, London, Volume 1 (pp. 191–199). Springer Singapore.
Wielemaker, J., Schrijvers, T., Triska, M., & Lager, T. (2012). Swi-prolog. Theory and Practice of Logic Programming, 12(1-2), 67–96
% Define symptoms
symptom(fever).
symptom(dry_cough).
symptom(tiredness).
symptom(aches_and_pains).
symptom(sore_throat).
symptom(diarrhoea).
symptom(conjunctivitis).
symptom(headache).
symptom(anosmia).
symptom(difficulty_breathing).
symptom(chest_pain).
symptom(loss_of_speech_or_movement).
% Define risk factors
risk_factor(elderly).
risk_factor(hypertension).
risk_factor(diabetes).
risk_factor(cardiovascular_disease).
risk_factor(chronic_respiratory_disease).
risk_factor(cancer).
risk_factor(male).
% Rules for diagnosis
% Rules for diagnosis
possible_infection(PatientID) :-
has_symptoms(PatientID),
assess_risk(PatientID).
has_symptoms(PatientID) :-
write('Enter symptoms for patient '), write(PatientID), nl,
get_symptoms(Symptoms),
member(Symptom, Symptoms),
(symptom_case_insensitive(Symptom) ->
write('Patient has '), write(Symptom), nl
;
write('Unknown symptom: '), write(Symptom), nl,
fail
).
assess_risk(PatientID) :-
write('Enter risk factors for patient '), write(PatientID), nl,
get_risk_factors(Factors),
memberchk(Factor, Factors),
(factor_case_insensitive(Factor) ->
write('Patient has risk factor: '), write(Factor), nl
% Helper predicates to get symptoms and risk factors
get_symptoms(Symptoms) :-
write('Enter symptoms separated by commas: '),
read_line_to_string(user_input, InputString),
split_string(InputString, ",", " ", Symptoms).
get_risk_factors(Factors) :-
write('Enter risk factors separated by commas: '),
read_line_to_string(user_input, InputString),
split_string(InputString, ",", " ", Factors).
% Example queries
% ?- possible_infection(1).
Topic
In the last decades, a common problem all countries face is the inability to meet the enormous demands of providing good medical services for their citizens and the shortage of medical expertise. This issue spikes in developing countries where both aspects reach tremendous levels.
Researchers worldwide dealt with the issues developing AI algorithms able to improve and accelerate traditional medical diagnostic methods.
Research the literature to identify and briefly describe an existing medical diagnosis system based on either fuzzy logic or a Bayesian framework. Explain how the system you chose applies the approach, and use it as example to describe how either fuzzy systems or Bayesian frameworks can be used for the development of intelligent medical systems (e.g. in diagnostic or other clinical tasks). Advance some ideas on what it would take to use the alternative approach for the system you identified, that is moving from fuzzy logic to Bayes, or vice versa.
Post
Based on fuzzy logic, the chosen medical diagnosis system is a hybrid intelligent system for predicting the course of Parkinson's disease (PD), as stated in the paper "A hybrid intelligent system for the prediction of Parkinson's Disease progression using machine learning techniques" by Nilashi et al., 2019.
The standard evaluation instrument for Parkinson's disease (PD) and a common way to measure parkinsonism is the Unified Parkinson's Disease Rating Scale (UPDRS), (ParkinsonsUK, 2022). The authors use an incremental machine learning technique called Incremental Support Vector Machine to predict UPDRS scores, specifically Total-UPDRS and Motor-UPDRS. Additionally, they use self-organizing maps for grouping jobs and non-linear iterative partial least squares for reducing the dimensionality of the data.
The application of fuzzy logic is relevant while handling the intricate and unpredictable characteristics of Parkinson's disease. The four main characteristics of Parkinson's disease (PD) are bradykinesia, stiffness, resting tremor, and poor postural instability. Early identification is essential since the existence and severity of these symptoms change throughout time. Given fuzzy logic's propensity to deal with ambiguity and imprecision, it makes sense, given the inherent ambiguity in PD diagnosis.
The suggested hybrid approach combines Non-linear Iterative Partial Least Squares (NIPALS), Self-Organizing Map (SOM), and Incremental Support Vector Regression (ISVR). It is emphasized that the ISVR, particularly, is a useful regression machine-learning method for real-time prediction (Nilashi et al., 2019). In order to minimize calculation time, the authors stress the value of taking new data into account without recalculating all of the training data and supporting incremental updates.
For the specified system, switching from fuzzy logic to a Bayesian framework would necessitate a paradigm change in methodology. Since fuzzy logic allows for degrees of truth, it naturally addresses uncertainty and imprecision, aligning with post-traumatic stress disorder's complex and changeable nature (Ahmadi et al., 2019). Conversely, the Bayesian framework is a probabilistic method that depends on conditional probabilities and necessitates a precise characterization of input-output relationships, which may oversimplify the complex nature of probability distribution. The problem would need to be reformulated regarding probabilistic dependencies and conditional probabilities to switch to a Bayesian approach. This could include estimating uncertainty using a more probabilistic approach, which might need to be more successful at capturing the nuances of PD as fuzzy logic. Moreover, the assumption of independence between variables in Bayesian models may not apply to Parkinson's disease (PD), as symptoms may be related.
In summary, fuzzy logic is used by the chosen medical diagnosis system to handle the complexity and variety of Parkinson's disease. A hybrid intelligent system is created by combining Non-linear Iterative Partial Least Squares, Self-Organizing Maps, and Incremental Support Vector Regression. Making the switch to a Bayesian approach would necessitate carefully analyzing the subtleties in PD and would result in the loss of the richness that fuzzy logic offers in managing imprecision and uncertainty.
References
Ahmadi, H., Gholamzadeh, M., Shahmoradi, L., Nilashi, M. and Rashvand, P. (2019). Diseases diagnosis using fuzzy logic methods: A systematic and meta-analysis review. Computer Methods and Programs in Biomedicine, [online] 161, pp.145–172. doi:https://doi.org/10.1016/j.cmpb.2018.04.013.
Nilashi, M., Ibrahim, O., Ahmadi, H., Shahmoradi, L. and Farahmand, M. (2019). A hybrid intelligent system for the prediction of Parkinson’s Disease progression using machine learning techniques. Biocybernetics and Biomedical Engineering, 38(1), pp.1–15. doi:https://doi.org/10.1016/j.bbe.2017.09.002.
In their 2019 paper, Nilashi et al argued that the chosen medical diagnosis system would predict the direction of Parkinson’s disease (PD). The system they proposed should be hybrid intelligent that used fuzzy logic approach with some aspects of machine learning. In particular, it involves the application of self-organizing maps, non-linear iterative partial least squares, and incremental support vector machines. Because of the irregularity of the symptoms of Parkinson’s disease, fuzzy logic is necessary for the handling of inexactness and ambiguity (de Souza et.al., 2021). Authors acknowledge the significance of the Unified Parkinson’s Disease Rating Scale (UPDRS), which is regarded as one of the most used evaluative scales, and recommend an increased use of incremental Machine learning to predict the outcomes of the UPDRS. An essential aspect of the proposed method is focused on real-time predictability, particularly when applied to Incremental Support Vector Regression.
A move from the fuzzy logic approach to the Bayesian framework gives rise to the “critical” perspective. This shift is not without its criticisms though as fuzzy logic lends itself to degrees of truth, uncertainty, and imprecision — attributes necessary to deal with PD’s complex and mutating nature. However, the Bayesian framework, although probabilistic, might simplify too much of the involved probabilistic distribution concerning PD (Taka et al., 2020). Nonetheless, in the Bayesian model we have a specification of what is means by interdependence of symptoms or how the inputs relate to the outputs and some times assume that they are non independent variables in situations where the complex ways these symptoms might interact do not exist.
On overall, the first article stresses the importance of fuzzy logic as related to the complexities surrounding PD and constructing rigid hybrid intelligent model. This opposition makes reasonable sense considering the uniqueness in PD as well as an eventuality if vagueness and uncertainty can be handled. This critical analysis examines pros as well as cons of the applied technology and warns not to move away from this type of decision about PD diagnosis due to the suggested paradigm shift.
References
de Souza, R.W.R., Silva, D.S., Passos, L.A., Roder, M., Santana, M.C., Pinheiro, P.R. and de Albuquerque, V.H.C. 2021. Computer-assisted Parkinson's disease diagnosis using fuzzy optimum-path forest and Restricted Boltzmann Machines. Computers in Biology and Medicine, 131, p.104260. doi:https://doi.org/10.1016/j.compbiomed.2021.104260.
Nilashi, M., Ibrahim, O., Ahmadi, H., Shahmoradi, L. and Farahmand, M. 2019. A hybrid intelligent system for the prediction of Parkinson’s Disease progression using machine learning techniques. Biocybernetics and Biomedical Engineering, 38(1), pp.1–15. doi:https://doi.org/10.1016/j.bbe.2017.09.002.
Taka, E., Stein, S. and Williamson, J.H. 2020. Increasing Interpretability of Bayesian Probabilistic Programming Models Through Interactive Representations. Frontiers in Computer Science, 2. doi:https://doi.org/10.3389/fcomp.2020.567344
Topic
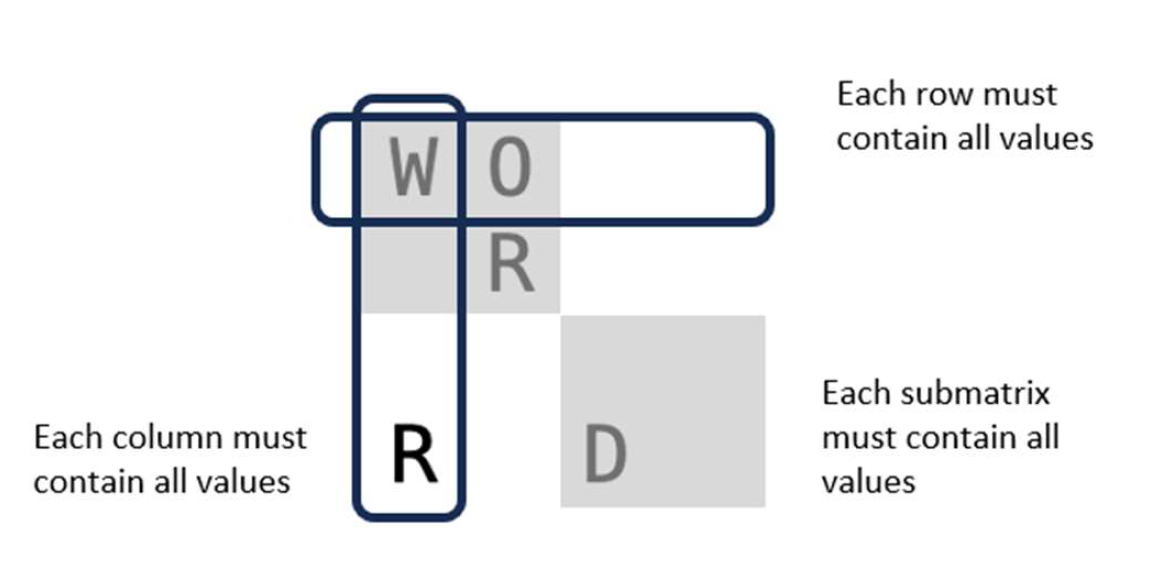
Create a software application that solves a puzzle game similar to Sudoku using genetic algorithms. The objective is to fill a grid of size 4x4 with four different letters so that each column, each row, and each of the four sub-grids of size 2x2 contain each of the letters only once
As an example, this is a successfully solved grid:
W
D
R
O
O
R
W
D
R
O
D
W
D
W
O
R
At the start of the game, a partially completed grid is provided by the user. Depending on the initial configuration, the puzzle might have no solution, one single solution or more than one solution. You decide the initial placement on the grid.
The conditions for letter placement on the 4x4 grid are as follows:
the four letters are all different from each other; you decide what letters to use as long as they are all different
the same single letter may not appear twice in the same row, column, or any of the four subgrids of size 2x2
Report
Chapter 1. INTRODUCTION
This report discusses the group project to develop pseudo-code and code that solves a Sudoku-like problem, using genetic algorithms. Sudoku represents a combinatorial optimization problem with high popularity as a pastime. Genetic Algorithms (GAs) mimic the evolutionary process of biological organisms and are used for search and optimization problems.
This report provides a brief introduction of the Sudoku-like problem provided for the assignment as well as GAs. Then key elements of GAs are discussed as well as their application to the specific problem and the corresponding pseudocode. The performance of the proposed solution is reviewed, by converting pseudocode to python code. It is shown that GAs can effectively solve a Sudoku-like problem. But the report also demonstrates how the tuning of parameters, genetic operators and elements like the fitness function impact performance and effectiveness and, with that, reviews limitations and potential areas for improvements.
Chapter 2. THE SUDOKU-LIKE PROBLEM
Sudoku-like problems are combinatorial problems. Sato and Inoue (2010, p. 23) explain that in its original form Sudoku is a 9x9 matrix, where each cell can take 9 different values, usually the numbers 1 to 9. The starting point has already some cells filled with values. The challenge is to fill all remaining cells with values, complying to the following rule: each value in each row, column and sub-matrix must be unique. The difficulty depends largely on the number and position of cells and their values provided as starting point.
Figure 1 shows the Sudoku-like problem discussed in this report. It has a 4x4 matrix and its cells can take the values of “W”, “O”, “R” or “D”. In this example, five cells are already filled and a solution for eleven other cells needs to be found, complying to the rule from above. To illustrate a solution to one cell: the submatrix on the top left has already three cells filled with the obvious solution “D” for the fourth cell.
Figure 1. The Sudoku-like Problem
Chapter 3. INTRODUCTION TO GENETIC ALGORITHMS
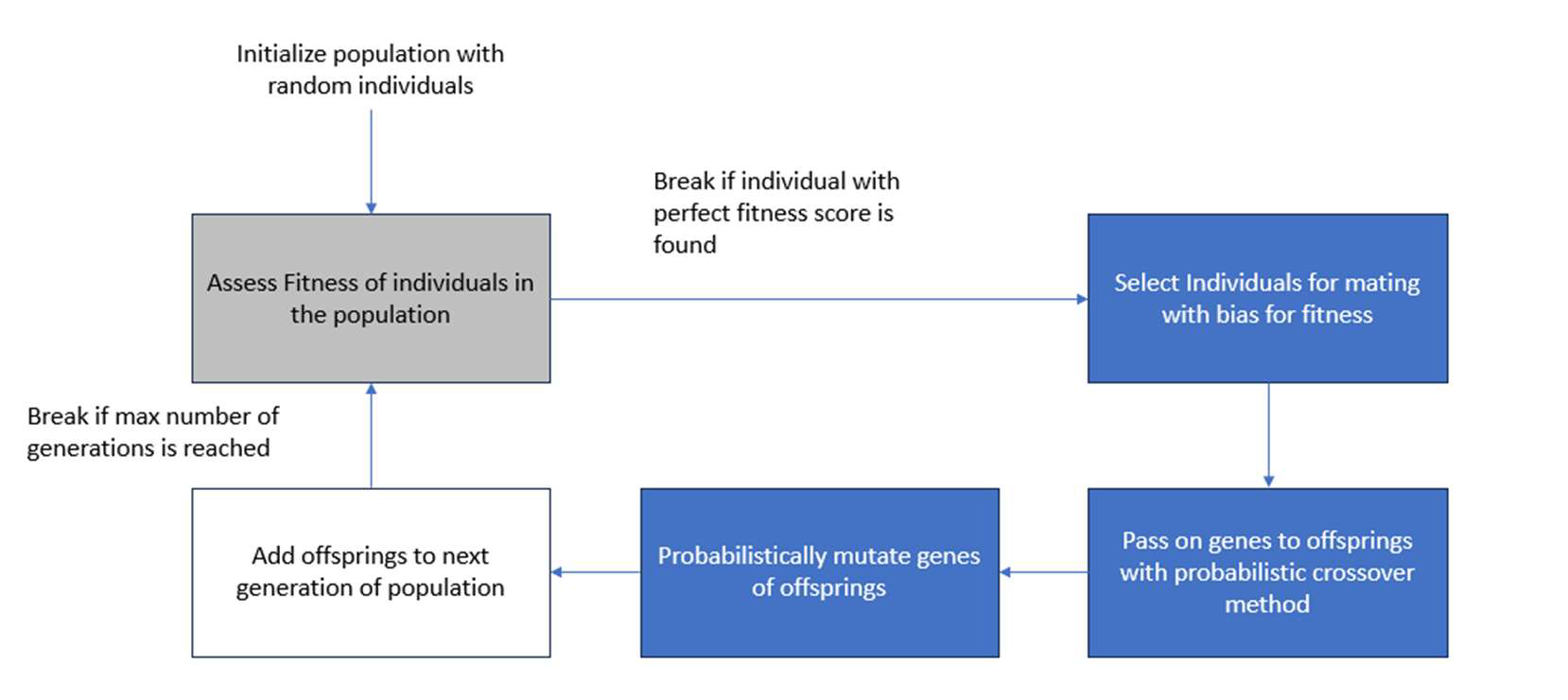
GAs mimic the evolutionary process of biological organisms as described by Darwin and others, following principles of natural selection and survival of the fittest (Basely, et. al., 1993a, p.1). While there is no accepted “general theory” explaining why GAs work (Basely, et. al., 1993a, p.7), they are used for search and optimization problems in many disciplines. When designing a GA several elements need to be considered. First, the problem and its solution are linked to the GA by encoding and evaluation (Negnevitsky, 2011, p. 221). When applying this to the Sudoku-like problem, each element of the matrix (see Figure 1) can be considered a gene that can take the instances of “W”, “O”, “R” or “D”, which is an example of value encoding. The entire matrix is then referred to as “chromosome” or individual, where all chromosomes or individuals have the same length. A fitness function is developed to evaluate the strength of an individual against the desired solution.
Next, genetic operators are run iteratively over a population, a defined number of individuals, creating a new generation each time until an individual with perfect fitness is found or the pre-determined nth generations is reached. Basic genetic operators are selection based on strength, mating, also referred to as crossover, and mutation of genes. (Negnevitsky, 211, p. 223). Figure 2 illustrates the basic schema of a genetic algorithm.
Figure 2. Basic Schema of a Genetic Algorithm
The following chapters will discuss the encoded problem, fitness function, genetic operators as well as pseudocode and code to solve the Sudoku-like problem in more detail.
Chapter 4. SOLUTION TO FITNESS FUNCTION
The role of the fitness function in the context of genetic algorithms is to quantify the quality of each candidate solution by mapping it to the real number with the convention that a higher fitness value corresponds to a better solution (Wirsansky, 2020). Sudoku is an example of a combinatorial optimisation problem, which means the goal is to find the best combination of discrete elements from a finite set (Mantere and Koljonen, 2007). When designing the fitness function, there were several considerations: ensuring completeness of the grid and uniqueness of values in each row, column and subgrid, and minimising repetition. The implemented fitness function checks each row, column and 2x2 subgrid to ensure that each value appears only once using a set, the data structure that can only contain unique values. Thus, the fitness score reflects the count of unique values in rows, columns, and subgrids, indicating how close the solution is to satisfying Sudoku rules while grids with repetitions within rows, columns, or subgrids are penalized by having their fitness score reduced. Thus, the objective of the genetic algorithm is to maximize the fitness function to achieve the highest possible score of 48.
Table 1 – Solution Candidates with Fitness Scores
Individuals
Fitness Score
40
44
Chapter 5. SOLUTION TO GENETIC OPERATORS
5.1 Selection of individuals for mating
Mallawaarachchi (2017) argues the idea of selection is to identify the fittest individuals to pass on their genes to the next generation. However, to ensure diversity throughout the evolution and not rule out genes or sequences of genes early on that might produce high fitness when mating with strong individuals, it is advisable to also allow weaker individuals to take part in the evolutionary process. Beasley et. al. (1993a, p. 3) therefore suggest selecting individuals randomly but favour individuals with higher fitness.
This is also referred to as roulette wheel selection (Negnevitsky, 2011, p. 225), where all individuals from the population get a slice of the roulette wheel but the individuals fitness score proportionally increases or decreases the slices. See table x for a simple example for a population with 4 individuals. Below is the pseudo code illustrating the parent selection function:
Pass in: individuals, individuals’ fitness scores
Randomly select an individual but weight likelihood by fitness score
higher fitness score has higher probability
Assign the selected individual to parent
Pass out: parent
Table 2 – Roulette Wheel Weights
Individuals
Index
Fitness Score
Likelihood for selection
X1
0
23
.46
X2
1
17
.34
X3
2
8
.16
X4
3
2
.04
Total
50
1.00
5.2 Crossover Approach
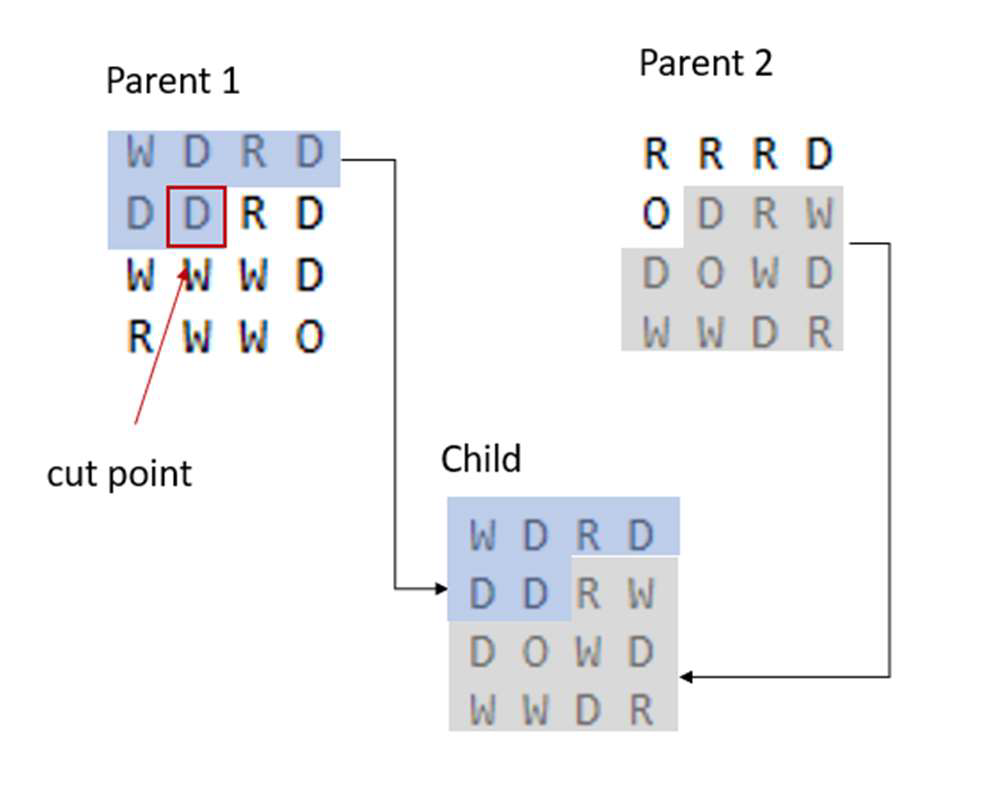
A 1-point-crossover is considered the “traditional” approach in GAs (Beasley, 1993b) and is used in the GA addressing the Sudoku-like problem. A 1-point-crossover randomly determines a cut point in the parents’ chromosome – because both parents have the same length determining it for parent 1 is sufficient – up to which the gene sequence of parent 1 populates and empty child matrix. The gene sequence of parent 2 populates after the cut point (Negnevitsky, 2011, p. 226). Because the initial grid in the Sudoku-like problem defines immutable genes, a simple 1-point crossover is also very suitable. The sequence of genes remains always intact and will not violate constraints set in the initial grid. The pseudocode below illustrates the approach (see also Figure 3).
Pass in: parent1, parent2
Define random cut point, that is between “1 and max length minus 1” of parent 1
Create an empty child grid
Copy gene sequence from first parent up to the cut point to child matrix
Copy gene sequence from second parent after the cut point to child matrix
Pass out: child
Figure 3. 1-point-crossover
5.3 Mutation
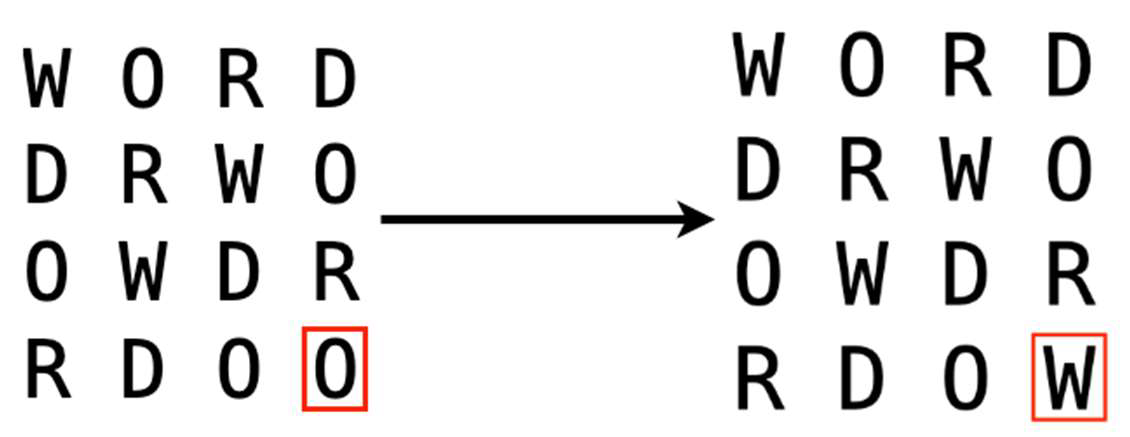
The mutation introduces randomness to the genetic algorithm allowing further exploration of the solution space (Wirsansky, 2020). Among several approaches to mutation, random resetting mutation was chosen as it was shown to be effective when solving sudoku puzzles with a genetic algorithm (Srivatsa et al., 2019). In this mutation operation, a random gene or parameter of an individual is selected, and its value is reset to a new random value from a given range (Yazıcı, 2019).
Figure 4. Random Reset Mutation
The function ensures that the mutation occurs only in the cells of the individual corresponding to empty cells of the initial grid, thus preserving the provided puzzle's configuration. The current value at the selected position is replaced with a new random letter. The picked value is ensured to be different from the one it is supposed to replace. The implementation of mutation fulfils two main requirements for mutation operations as defined by Kramer (2017): reachability as it allows reaching any valid solution through a series of mutations and unbiasedness as each position is selected randomly. The pseudocode below illustrates the approach.
Pass in: initial grid, individual to mutate
Pick random position in[i][j] grid
IF position is NOT empty in the initial grid repeat until empty position is found
Exchange letter with randomly picked qualified letter
Pass out: mutated individual
Chapter 6. BRINGING IT ALL TOGETHER
6.1 Population Size and Numbers of Generations
The number of generations is set to 1000 as the combination of random resetting mutation with the one-point crossover is shown to require about 1000 generations to lead to a solution for the sudoku puzzle (Srivatsa et al., 2019).
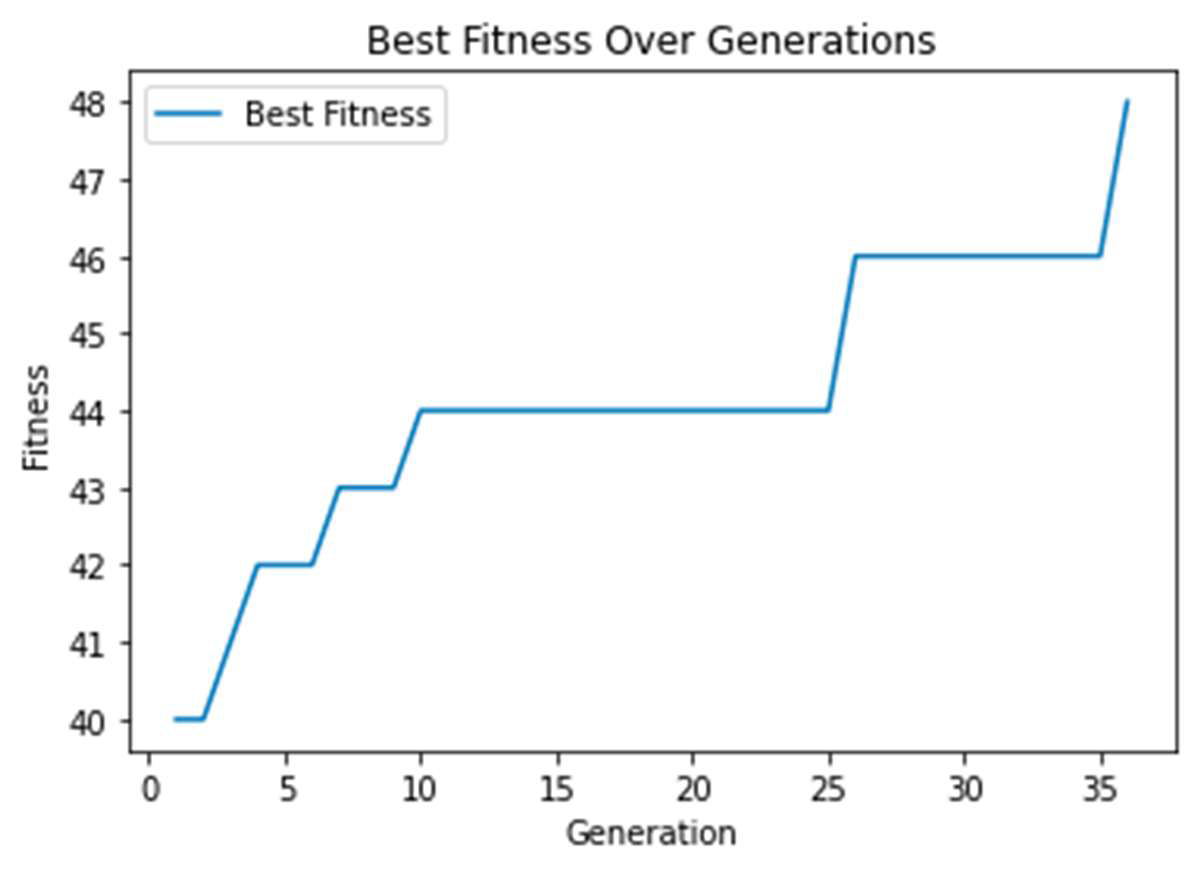
To determine the optimal population size, the approach chosen is to start with a bigger value at first as a bigger population size can enable better exploration of the solution space (Wirsansky, 2020). Following Sato and Inoue (2010), the population size is initially set to 150. In this case, the solution is found in the 36th generation when trying a grid with a filled row.
Figure 5. The maximum fitness over the generations for population size of 150
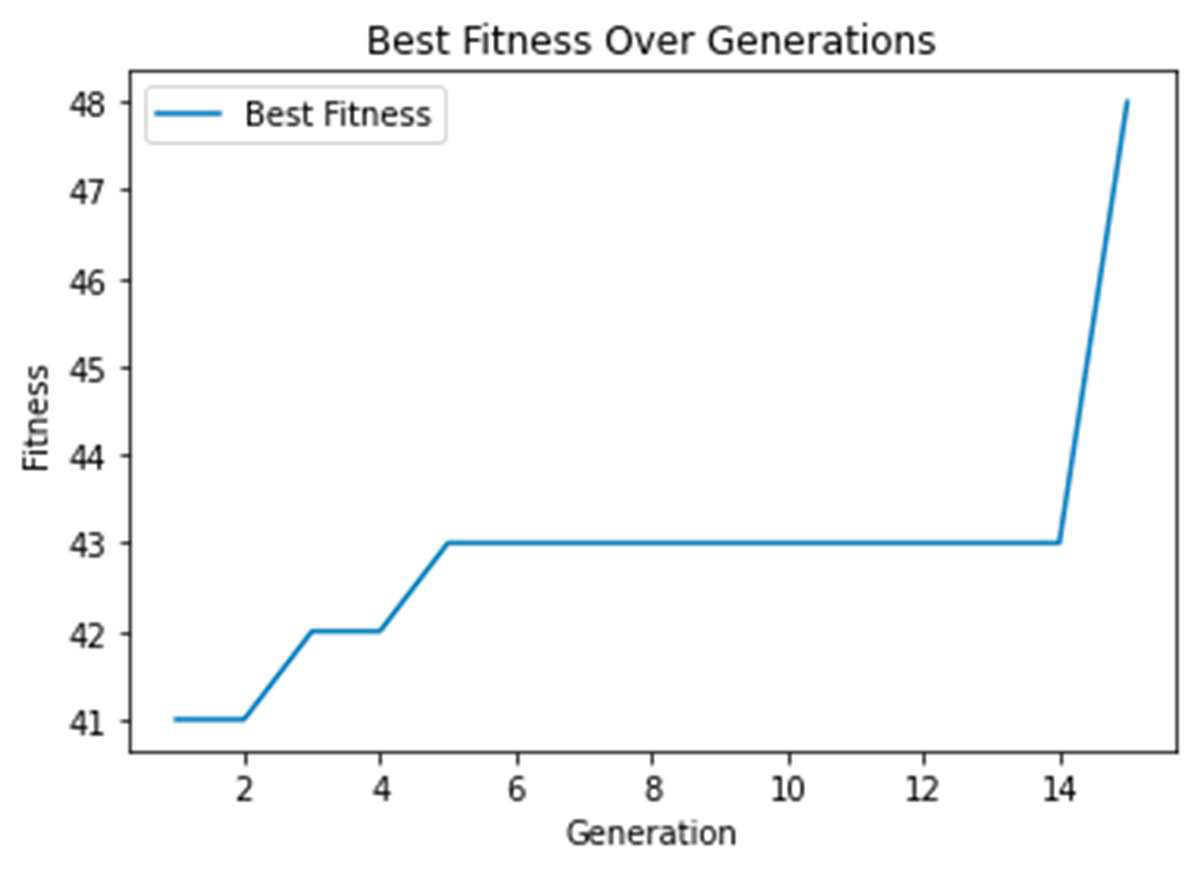
Next, the population size is reduced to 100 as this value is put forward as one of the optimal numbers for the genetic algorithm (Patil and Pawar, 2015). In this case, the solution is reached in the 15th generation. The convergence to the solution may have happen faster due to higher fitness scores in the initial stages, so in the larger populations, the individuals with higher fitness can dominate, decreasing the population's diversity, and eliminating promising individuals (Chen et al., 2012).
Figure 6. The maximum fitness over the generations for population size of 100
6.2 Applying Selection, Crossover and Mutation
To ensure that the best-performing individual is not lost, elitism is implemented meaning the individuals with the highest fitness score from one generation are directly copied to the next generation without undergoing crossover or mutation. Elitism can be beneficial in preserving good solutions and preventing the loss of valuable genetic material thus expediting the solution search (Wirsansky, 2020). The crossover rate of 0.9 and the mutation rate of 0.03 are chosen as these are the most used default values for the genetic algorithms (Hassanat et al., 2019).
6.3 Termination
Two termination criteria are used. First, if a solution is found where the best fitness is equal to the highest fitness value of 48, the algorithm terminates. This condition ensures that the algorithm stops when it finds a solution with the optimal placement of letters in the grid. Secondly, the genetic algorithm stops running after reaching the maximum number of generations.
6.4 Results
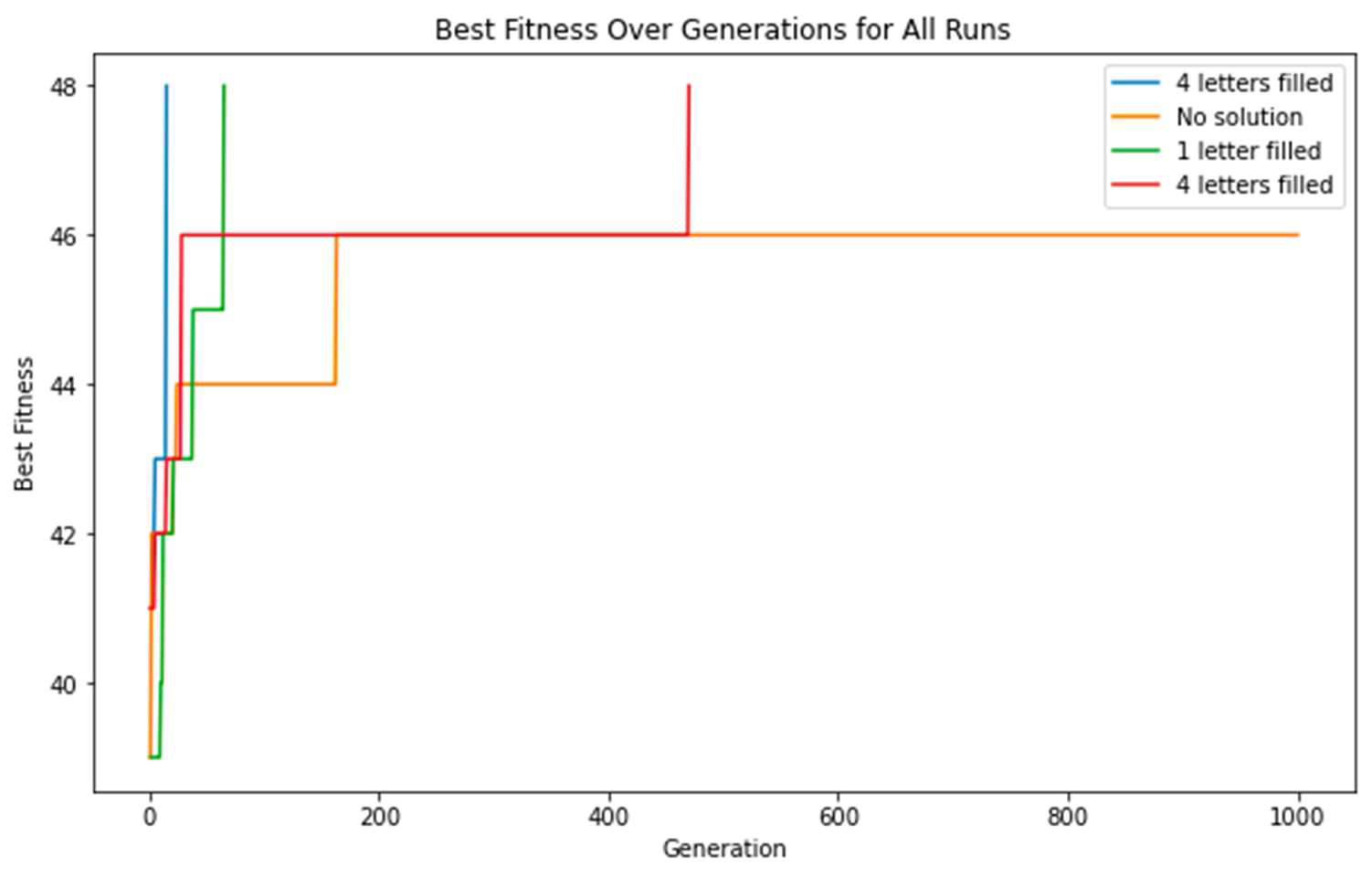
The genetic algorithm is run for four different grids.
Table 3 – Results of the runs
Initial individual
Generation reached
Final individual
Results
15
The initial grid has a complete row of letters. The algorithm successfully found a solution in 15 generations. The presence of pre-filled letters likely accelerates the convergence of the genetic algorithm.
1000
The algorithm does not find a solution within the maximum number of generations. This suggests that the initial configuration might be challenging or even unsolvable, given the constraints.
65
With only one pre-filled letter, this grid takes longer to converge than the first one, and the solution is found in the 65th generation.
470
The algorithm finds a solution in 470 generations. The longer convergence time compared to the first grid with a completed row as well could be attributed to the different configuration and the need for the algorithm to explore a larger search space.
The results highlight the sensitivity of the genetic algorithm to the initial configurations. Some configurations lead to faster convergence and successful solutions, while others might pose challenges or be unsolvable within the specified constraints and the given number of generations.
Figure 7. The maximum fitness over the generations for all runs
Chapter 7. LIMITATIONS AND POTENTIAL IMPROVEMENTS
The fitness function could have provided more nuanced feedback to the genetic algorithm by including different penalties for constraint violations (Mantere and Koljonen, 2007). In addition, the fitness function does not explicitly encourage diversity in the population. Fitness sharing could have been utilized to encourage exploration of the solution space and make sure the optimal solution is reached (Ragalo and Koljonen, 2007).
A major concern for GAs is a lack of diversity in the population and, hence, optimizing towards a local minimum. Different approaches to genetic operators are discussed to improve diversity. For parent selection, Drezner and Drezner (2020) discuss alternatives to the roulette wheel approach, for example seek for most different alternative as second parent towards the select first parent 1. Also, the authors suggest as new approach select two members at random and assign a probability to select the one with higher fitness and have a different, random individual assigned as second parent. Varying the probability allows to control for diversity seeking behaviour versus fast evolution.
Arguably, the crossover approach is of high importance to the GA’s performance (Mallawaarachchi (2017). If the GA does not perform as expected, alternative crossover approaches should be considered. Likely favourable are approaches that keep the sequences of genes intact, for example 2-point- or multi-point-crossover or uniform cross-over. Those can be tested on a trial-and-error basis as advantages depend on population size and chromosome length (Beasley, 1993b, pp-2-3).
There are several weaknesses in the mutation approach. First, the mutation only modifies a single cell at a time, which may result in incremental changes especially for grids of bigger size. Choosing several random cells at once or implementing inversion or scramble mutation could be the potential solution. In addition, the mutation operation does not explicitly consider the constraints of the puzzle. While the initial configuration is preserved, the mutation may result in an individual violating Sudoku rules by adding a repetitive value. In this case, the swap mutation may be considered, which is commonly used for similar problems (Sato and Inoue, 2010).
Further exploration could involve experimenting with parameters, such as population size, the maximum number of generations, crossover rate and mutation rate. Implementing additional stopping criteria, like a threshold for improvement over consecutive generations, may enhance the algorithm's adaptability.
Chapter 8. CONCLUSIONS
The genetic algorithm developed for solving the 4x4 Sudoku-like puzzle demonstrated its ability to find solutions efficiently for several initial grid configurations. The use of elitism, roulette wheel selection for parent individuals, 1-point-crossover and random resetting mutation strategies contributed to the exploration and exploitation of the solution space, while the termination criteria ensured efficient convergence. However, the algorithm's performance varied across different scenarios, which suggests opportunities for refinement and optimization. Continued experimentation and parameter tuning could enhance the algorithm's robustness and efficiency.
Beasley, D., Bull, D.R. and Martin, R.R. (1993b) ‘An overview of genetic algorithms: Part2, fundamentals’ University Computing, 1993, 15(4) 170-181. Available at:https://mat.uab.cat/~alseda/MasterOpt/Beasley93GA2.pdf.
Chen, T., Tang, K., Chen, G. and Yao, X. (2012). A large population size can be unhelpfulin evolutionary algorithms. Theoretical Computer Science, [online] 436, pp.54–70.
Drezner, Z. and Drezner, T.D. (2020) ‘Biologically Inspired Parent Selection in Genetic Algorithms’,Annals of operations research, 287(1), pp. 161–183. Available at:https://doi.org/10.1007/s10479-019-03343-7.
Hassanat, A., Almohammadi, K., Alkafaween, E., Abunawas, E., Hammouri, A. and Prasath,V.B.S. (2019). Choosing Mutation and Crossover Ratios for Genetic Algorithms—A Review with a New Dynamic Approach. Information, 10(12), p.390.doi:https://doi.org/10.3390/info10120390.
Kramer, O. (2017) Genetic Algorithms. Genetic Algorithm Essentials, pp.11-19.
Mantere, T. and Koljonen, J. (2007) Solving, rating and generating Sudoku puzzles withGA. In 2007 IEEE congress on evolutionary computation (pp. 1382-1389). IEEE.
Mallawaarachchi, V. (2017) ‘Introduction to Genetic Algorithms — Including ExampleCode’, July 8, 2017. Towards Data Science. Available at: https://towardsdatascience.com/introduction-to-genetic-algorithms-including-example-code-e396e98d8bf3
Negnevitsky, M. (2011) Artificial Intelligence : a guide to intelligent systems / Michael Negnevitsky. Harlow, England: Pearson.
Patil, V.P. and Pawar, D.D. (2015) The optimal crossover or mutation rates in genetic algorithm:A review. International Journal of Applied Engineering and Technology, 5(3), pp.38-41.
Ragalo, A. and Pillay, N. (2018). An investigation of dynamic fitness measures for genetic programming. Expert Systems with Applications, 92, pp.52-72.
Sato, Y. and Inoue, H. (2010) Solving sudoku with genetic operations that preserve building blocks. In Proceedings of the 2010 IEEE Conference on Computational Intelligence and Games (pp. 23-29). IEEE.
Srivatsa, D., Teja, T.K., Prathyusha, I. and Jeyakumar, G. (2019). An empirical analysis of genetic algorithm with different mutation and crossover operators forsolving Sudoku. In Pattern Recognition and Machine Intelligence: 8th International Conference, PReMI 2019, Tezpur, India, December 17-20, 2019, Proceedings, Part I (pp. 356- 364). Springer International Publishing.
Wirsansky, E. (2020) Hands-On Genetic Algorithms with Python: Applying genetic algorithms to solve real-world deep learning and artificial intelligence problems. [online] Google Books. Packt Publishing Ltd.