In [ ]:
# Import libraries
import requests
from bs4 import BeautifulSoup
# Fetch the webpage
res = requests.get('http://v.media.daum.net/v/20170615203441266')
# Parse the webpage
soup = BeautifulSoup(res.content, 'html.parser')The soup.find_all() function is used to locate all instances of <span> elements with the specified class.
The class_='txt_info' argument specifies that only <span> elements containing the class 'txt_info' should be retrieved.
All matching <span> elements are collected in the mydata variable as a list of objects.
In [ ]:
# Extract the required data
mydata = soup.find_all('span', class_='txt_info')In [ ]:
for data in mydata:
print(data.string)How to Find Data in Chrome¶
- Open Developer Tools in the Chrome browser (shortcut: press F12 on your keyboard).
- Use your mouse to click on the element or data you want to extract.
- Identify the element's tag and class or other attribute values.
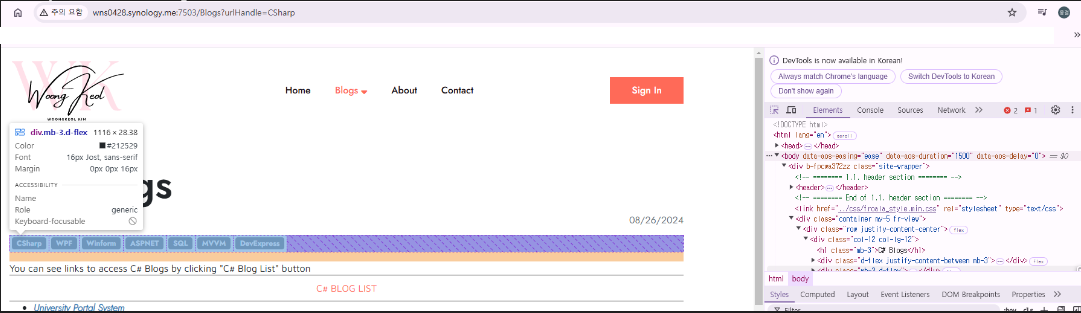
- Use this information to refine your find_all query (or equivalent function in your chosen library) for data extraction.
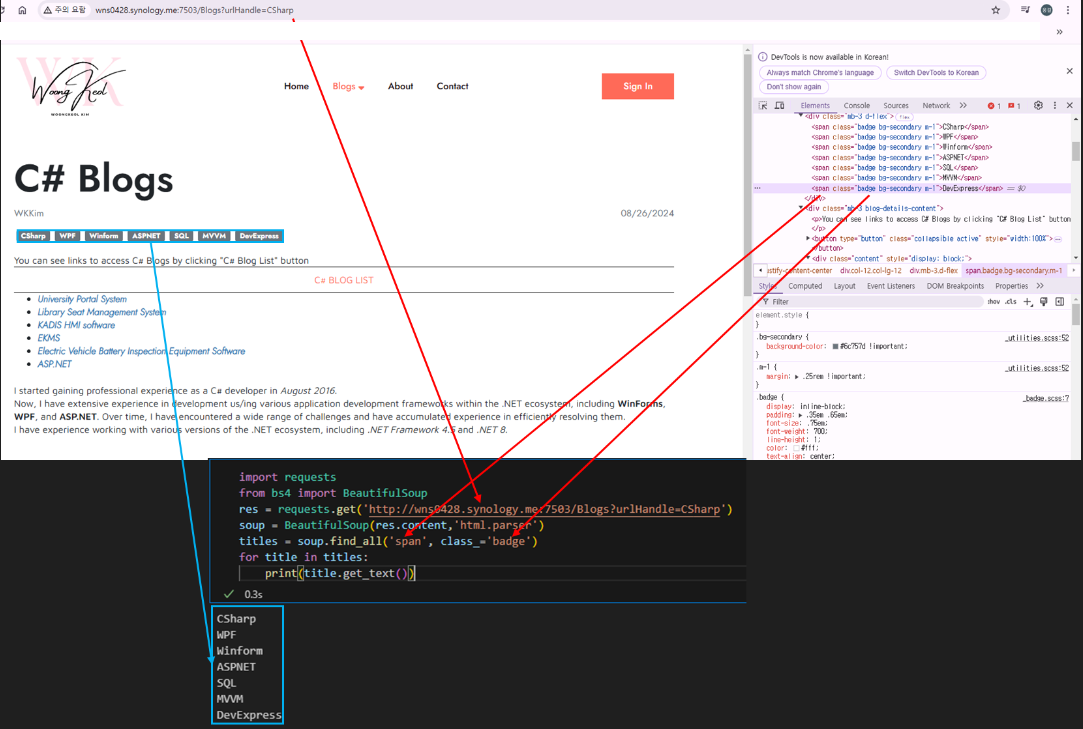
In [ ]:
import requests
from bs4 import BeautifulSoup
res = requests.get('http://wns0428.synology.me:7503/Blogs?urlHandle=CSharp')
soup = BeautifulSoup(res.content,'html.parser')
titles = soup.find_all('span', class_='badge')
for title in titles:
print(title.get_text())CSharp WPF Winform ASPNET SQL MVVM DevExpress
Powerful Crawling Tip¶
Extract Nested Data Step-by-Step
- Directly extract <li> tags from the webpage.
- Result: The output resembles the second screenshot.
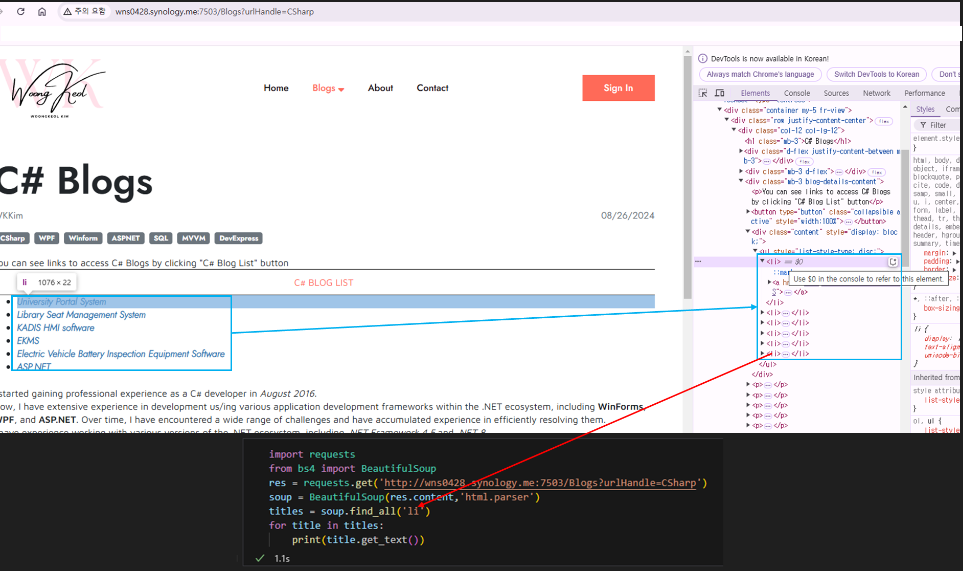
In [ ]:
import requests
from bs4 import BeautifulSoup
res = requests.get('http://wns0428.synology.me:7503/Blogs?urlHandle=CSharp')
soup = BeautifulSoup(res.content,'html.parser')
titles = soup.find_all('li')
for title in titles:
print(title.get_text())Refined Approach:
- Locate the parent <div> tag with class="content".
- Extract <li> tags from within this specific section.
- Result: The desired output, as shown in the fourth screenshot.
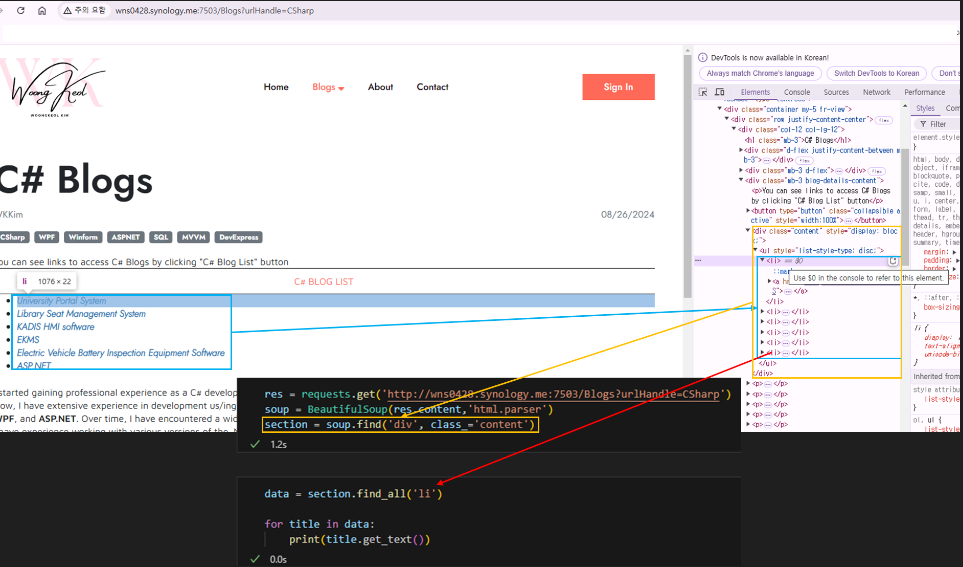
In [ ]:
res = requests.get('http://wns0428.synology.me:7503/Blogs?urlHandle=CSharp')
soup = BeautifulSoup(res.content,'html.parser')
section = soup.find('div', class_='content')In [ ]:
data = section.find_all('li')
for title in data:
print(title.get_text())
University Portal System Library Seat Management System KADIS HMI software EKMS Electric Vehicle Battery Inspection Equipment Software ASP.NET
Crawling Data Preprocessing¶
Examples of using string functions such as `strip()` and `split()`
In [ ]:
for index, title in enumerate(data):
# Split text into a list of words, and print the result
# The f-string format: f'{variable1}.{variable2}' allows dynamic insertion of variables into the string
print(f'{index+1}.{title.get_text().split()}')1.['University', 'Portal', 'System'] 2.['Library', 'Seat', 'Management', 'System'] 3.['KADIS', 'HMI', 'software'] 4.['EKMS'] 5.['Electric', 'Vehicle', 'Battery', 'Inspection', 'Equipment', 'Software'] 6.['ASP.NET']
In [ ]:
for index, title in enumerate(data):
# Eemove any leading or trailing occurrences of ' System'
# The f-string format: f'{variable1}.{variable2}' allows dynamic insertion of variables into the string
print(f"{index+1}.{title.get_text().strip(' System')}")1.University Portal 2.Library Seat Managemen 3.KADIS HMI softwar 4.EKM 5.Electric Vehicle Battery Inspection Equipment Softwar 6.ASP.NET